ツールカテゴリー記事の一覧です
VScodeでWSL上のRailsアプリをデバッグする方法
CentOS, Linux, PC, Ruby, VScode, Windows, WSL2, ツール, 紹介
皆さんはRuby on Railsでアプリを作成した後、そのデバッグをどのように行っているでしょうか?
様々な方法が考えられると思いますが、実はVScodeでもデバッグを行うことが可能です。
今回はWSL2で構築したLinux環境にVScodeから接続し、その中のrailsアプリのデバッグを行う方法について解説しましたので、ぜひ参考にしてみてください!
実行環境
はじめに説明したように、今回はまずWSL2を使ってWindows上にLinux環境を構築してから、railsアプリのデバッグを行います。
今回の実行環境はこちらになります
Windows11
WSL2
CentOS7
Rails 5.2.6.2
ruby 2.7.7
VScode1.74.3
WSL2でLinux環境の構築
まずは、WSL2上でLinuxの環境構築をする必要がありますが、WSL2のインストール方法については以前のブログの途中で紹介していますので、分からない方はそちらで確認してください。
ただ、以前の記事ではUbuntuをインストールしているため、今回のCentoOS7のインストール方法とは異なる点にご注意ください。
Rubyのインストール
続いて、Rubyのインストール方法を紹介します。
今回はrbenvを入れた後に、それを経由してrubyのインストールを行います。
まずは以下のコマンドを実行してrbenvと、ruby-buildをインストールしてください
# rbenvインストール $ git clone https://github.com/sstephenson/rbenv.git ~/.rbenv # ruby-buildインストール $ git clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-build
続いて環境変数へPath設定を行います
echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profile echo 'if which rbenv > /dev/null; then eval "$(rbenv init -)"; fi' >> ~/.bash_profile # 環境変数を反映 source ~/.bash_profile
続いてrubyをインストールします。今回は例として2.7.7をインストールしていますが、使用したいバージョンを指定すれば、それのバージョンのインストールができますので、適宜変更してください。
# rubyインストール rbenv install 2.7.7 # rbenv の再読み込み rbenv rehash # ローカルへ反映設定(ターミナル) rbenv local 2.7.7 # グローバルへ反映設定(全体) rbenv global 2.7.7
最後にbundlerとrailsのインストールを行います。以下のコマンドを実行してください。
# bundler のインストール gem install bundler # rails のインストール gem install rails
これでrailsまでのインストールは完了になります。railsアプリの作成については説明しませんので、デバッグに使用するアプリはそれぞれ用意してみてください。
VScodeのインストール
それではVScodeと、必要なプラグインのインストールについて説明します。
VScodeのインストール
まずはVScodeをインストールします。
公式サイトより Download for Windows ボタンを押すと自動でダウンロードが始まります。
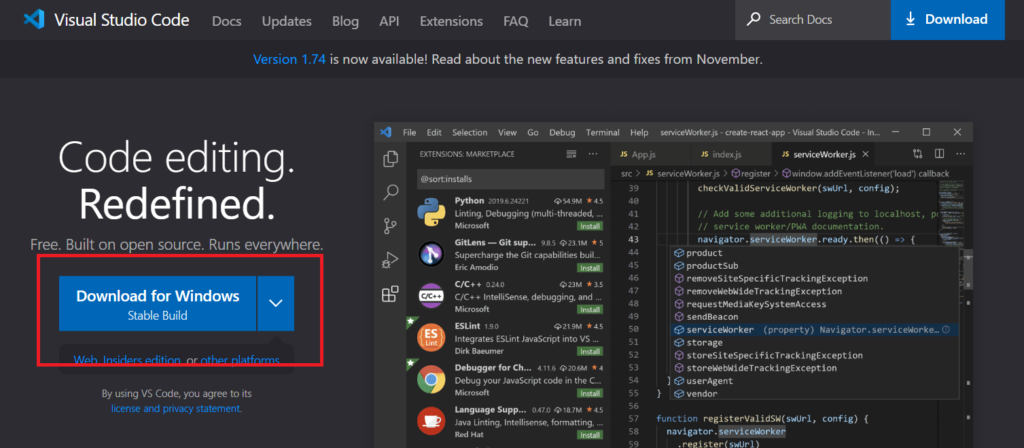
それが終わったら、そのファイルを開いてインストーラーを開きます。特に設定したい内容がなければそのままインストールして問題ありません。
VScodeの起動までできたらインストールは完了です。
プラグインのインストール
まずはVScodeでRubyを扱うためのプラグインをインストールします。
Vscodeを起動して、サイドメニューから拡張機能を選択し「Ruby」と検索してください。
候補がいくつか表示されると思いますが、「Ruby」と今回はrailsも使いますので「Ruby on Rails」をインストールしてください。
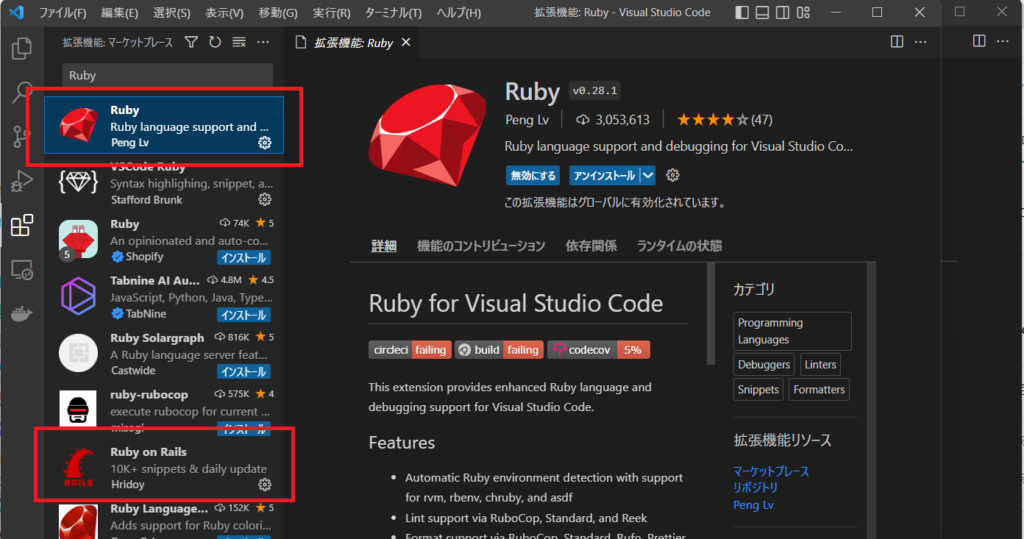
また、今回はWSL上のrailsアプリをデバッグするため、そのままではアプリの存在するディレクトリにアクセスすることができません。
そのため、VScodeからWSLにアクセスするためのプラグインもインストールする必要があります。
先ほどと同様に「WSL」と検索し、表示される “WSL” という拡張機能をインストールしてください。こちらがWindowsとLinux環境を繋げるプラグインになります。

VScodeでデバッグを行う
CentOS7と接続
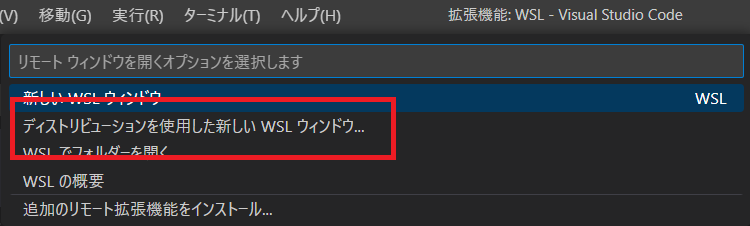
先ほどのプラグインをインストールすると、左下に緑色の表示が出てくるので、そちらをクリックしてください。
するとVscodeの上部に「リモートウィンドウを開くオプションを選択します」という表示が出てくるので、その中の「ディストリビューションを使用した新しい WSL ウィンドウ…」を選択します。
すると、WSL上にあるディストリビューションが表示されますので、接続したいもの (例ではCentOS7) を選んでください。
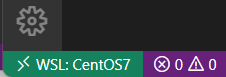
新しく開いたウィンドウの左下に “WSL : CentOS7” と表示されていれば接続成功です。
必要なgemのインストール
接続が完了すると、CentoOS7のディレクトリを開くことができるようになりますので、railsアプリの入ったディレクトリを選択して開いてください。
デバッグの際には以下のgemが必要になりますので、インストールされていない場合はGemfileに以下を記述してインストールしてください。
group :development do gem 'ruby-debug-ide' gem 'debase' end
VScode上でデバッグの設定
続いて、VScodeのデバッグ機能を使うための設定を行います。
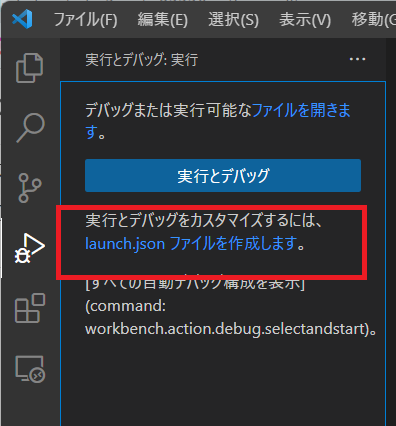
サイドメニューから”実行とデバッグ”を選択してください。
出てきた表示の中、「実行とデバッグ」の下にある「launch.jsonファイルを作成します。」を押してください。するとVScodeの上部に「デバッガーの選択」の表示が出てくるので、Ruby を選択してください。そうすると、自動でlaunch.jsonというファイルが作成されます。
続いても選択肢が表示されると思いますが、今回はrails アプリのデバッグを行うので、”Rails Server” を選択してください。
そこまで選択すると、launch.jsonファイルの中に自動でデフォルトの内容が記述されます。
launch.json ファイルの編集
先ほど、デバッグのために必要なjsonファイルを作成しましたが、その状態ではデバッグをしようとしてもエラーが表示される場合がありますので、それぞれに合わせた設定をする必要があります。
今回は、下記のようにjsonファイルを編集してください。
{
"version": "0.2.0",
"configurations": [
{
"name": "Debug Rails server",
"type": "Ruby",
"request": "launch",
"cwd": "${workspaceRoot}",
"useBundler": true,
"pathToBundler": "/home/ユーザー名/.rbenv/shims/bundle",
"pathToRDebugIDE": "/ruby-debug-ideまでのパス/ruby-debug-ide-0.7.3",
"program": "${workspaceRoot}/bin/rails",
"env": {
"RAILS_ENV": "development"
},
"args": [
"server",
"-b",
"0.0.0.0",
"-p",
"3000"
]
},
]
}
まず、今回はBundlerを使って実行するので35行目に “useBundler” のオプションを有効にしています
その次の36,37行目では、それぞれデバッグに使う bundle と ruby-debug-ide までのパスを記述しています。このパスは使用している環境によって異なりますので、適宜変更してください。
42か47行目の args: にはデバッグ実行時に渡す引数を設定することができますので、サーバー起動時のオプションも同時に設定します。
これでjsonファイルの編集も完了です。
デバッグの実行
そこまで編集すると、実行ボタンが表示されますので、デバッグで使用する構成を選んで、実行を行うとデバッグを行うことができます。
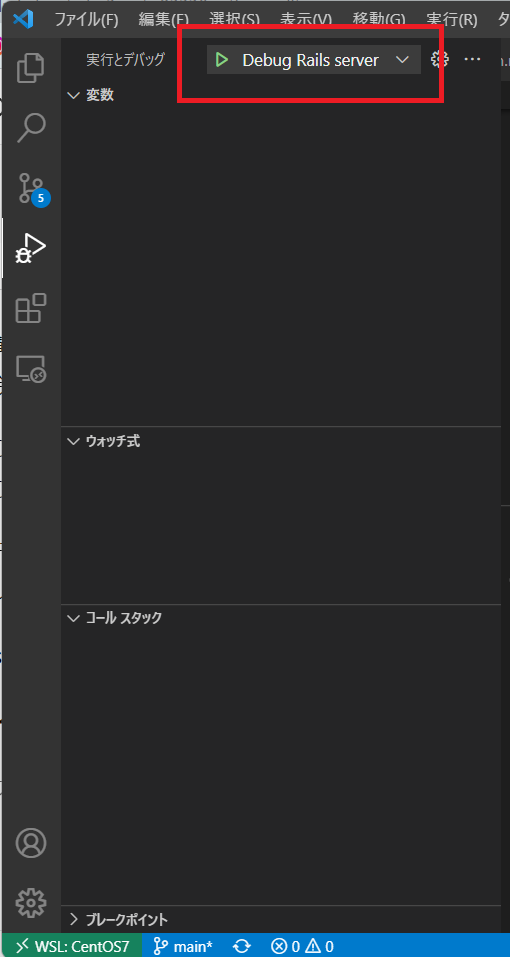
もちろんブレイクポイントも設定することができます。
処理を止めたい箇所の左側をクリックすると、その箇所に赤いマークが表示されブレイクポイントが設定されます。その状態でデバッグを実行するとその箇所で止まり、上の画像の欄にどのような値を持っているか等の情報が表示されます。
まとめ
いかがでしたでしょうか。VScodeでのデバッグは一度設定すれば、その後は実行ボタンを押すだけでデバッグを行うことができます。また、今回のようにWSL上のアプリであっても、VScodeから接続することが可能なので、作業効率も上げることができます。
もし、知らなったという人は、今回の記事を参考にデバッグを試してみてください!
【Linux】環境変数の設定方法と注意点
Linux, PC, Ubuntu, Windows, WSL2, ツール, 紹介
PC上で様々なプログラムを実行する時に重要になるのが、環境変数です。環境変数という言葉は聞いたことがあっても、実際にどういったものなのか、どうやって使うのか?については知らないという方もいらっしゃるかもしれません。
しかし、環境変数を理解しておくことは、PCで何か操作をする上で重要な内容になりますので、今回は環境変数について紹介していきたいと思います。
実行環境
今回はLinuxで環境変数の設定を行っていますが、Macでも同様に設定することが可能です。
ディストリビューションは以下の通りです。
Description : Ubuntu 22.04.1 LTS
補足
今回は bash(バッシュ) の記述で説明を行っています。
MacはOSがCatalinaになってから、標準のターミナルが bash から zhs(ズィーシェル) に変更されているため、シェルを bash に切り替えてから読み進めてください。
環境変数とは
まず、環境変数とは何かについて説明していきたいと思います。
環境変数とは変数の一種であり、OSに値を保存して利用者やプログラムから設定・参照できるようにしたものです。
また、詳しくは後述しますが環境変数は、ローカルのみ、ログインユーザー毎、全ユーザーの環境変数という様に分けることができ、これによって使える範囲等が異なってきます。
環境変数の確認方法
それでは、まずは実際に設定されている環境変数を確認する方法を紹介します。
環境変数を一覧で表示
設定されている環境変数を一覧で表示したいというときは以下のように “env” コマンドを実行します。
$ env
実行すると環境変数が一覧で表示されます。
$ env SHELL=/bin/bash WSL2_GUI_APPS_ENABLED=1 WSL_DISTRO_NAME=Ubuntu : PATH=/usr/local/sbin:/usr/local/bin・・・ HOSTTYPE=x86_64 :
環境変数を絞り込んで表示
先ほどのように一覧で表示すると、数が多くて分かりにくいということがあると思います。その場合は以下のように “grep” コマンドを使って、表示する変数を絞り込むことができます。
$ env | grep 検索したい文字列
例として、検索したい文字列に「WSL」という文字を入れて実行すると以下のような表示が出てきます。
$ env | grep WSL WSL2_GUI_APPS_ENABLED=1 WSL_DISTRO_NAME=Ubuntu WSL_INTEROP=/run/WSL/9_interop WSLENV=WT_SESSION::WT_PROFILE_ID
もちろん、表示される環境変数は設定されている内容によって変わりますので、色々な文字列で試してみてください。
特定の変数を表示
変数名が分かっていて、その値を確認したいというときは “echo” コマンドを使って確認することができます。変数名は “$変数名” で指定します。
$ echo $変数名
例として、変数名LANGの値を確認すると以下のように表示されます。
$ echo $LANG C.UTF-8
先ほどまでとは違って変数名を指定しているので、値だけが表示されます。
環境変数の設定方法
使用されている環境変数が確認できたところで、次は実際に環境変数を設定する方法について紹介します。
環境変数の追加
新しく環境変数を追加するには、以下のように “export” コマンドを使用します。
$ export 変数名=値
例として「変数名:hoge, 値:abc」といった環境変数を追加する場合は以下のようにコマンドを実行します。実際に設定されたかどうかは確認しないと分からないので、それも確認します。
$ export hoge=abc $ env | grep hoge hoge=abc
先ほど説明したgrepコマンドを使うと、問題なく設定されていることが確認できます。
また、PATHのように値が後ろに追加されるようにしたい場合は以下のようにして追加することができます。
$ export hoge=$hoge:def $ env | grep hoge hoge=abc:def
環境変数の削除
環境変数を削除する場合は以下のように “unset” コマンドを実行します。
$ unset 変数名
例として、先ほど追加した環境変数hogeを削除します。
$ unset hoge $ env | grep hoge (何も表示されなくなる)
環境変数を設定する際の注意点
これで、環境変数の追加、削除の方法が理解できたと思いますが、この時に注意しなければならないことがあります。それは上記で設定したコマンドは”ターミナルを再起動すると元に戻ってしまう“ということです。
つまり、毎回同じ環境変数を使う場合でも、最初に環境変数の追加をしなければならなくなってしまいます。これが初めの方で少し触れた、ローカルのみの環境変数になります。
なので、永続的に環境変数の設定をしたいという場合には、アカウント毎の環境変数か、システム全体の環境変数を設定する必要があります。その場合は以下のファイルを直接編集することで行うことができます。
【~/.bash_profile】
ログインのたびに実行されます
【~/.bashrc】
シェル(bash)ログインで毎回読込まれ実行されます
【/etc/profile】
全ユーザーに適用されるデフォルトの設定ファイルです。PC起動時に読み込まれます。
【~/.bash_login】
ログインして~/.bash_profileが存在しない場合にのみ、存在していれば実行されます
【~/.profile】
ログインして~/.bash_profile ・ ~/.bash_loginが存在しない場合にのみ、存在していれば実行されます
ログイン時に読み込まれるものはログインユーザー毎の環境変数であり、別アカウントでログインした際には適用されません。全ユーザーの環境変数を設定する際には【/etc/profile】を編集します。
編集するには、先で紹介したコマンドをそのまま記載すればよいので、編集したいファイルを選んで [export hoge=abc] といった内容を追記してください。
まとめ
いかがでしたでしょうか。環境変数について簡単に設定方法などを説明しましたが、実際にコマンドを実行してみると、より理解が深まると思いますのでご自身のPCでも試してみてください。
また、環境変数の種類を意識しないでいると、上手く反映されないということがありますので、実行する際には注意してみてください。
WSL2を使ってDocker開発環境を構築する方法を紹介!
BtoC, Docker, PC, Ubuntu, Windows, WSL2, ツール, 紹介
現在、アプリケーションの開発環境の構築をDockerで行うということが一般的になってきました。ただし、これまではWindows環境で試そうとすると複雑な手順が多く、気軽に試すということが難しいものでした。
しかし、WSL2 (Windows Subsystem for Linux 2) の登場により、WindowsOS上で互換性の高いLinux環境の構築が可能になり、高速でDockerを動かせるようになりました。
そこで今回はWindows上でWSL2を用いてDocker開発環境を構築する方法を紹介します。
また、今回はUbuntuを使用しますので、そちらもWSL2と合わせてインストールします。
実行環境
今回は以下の環境で実行します。
Windowsバージョン : 11 Pro 21H2
OS ビルド : 22000.1335
Ubuntu : 20.04
Docker Desktop : 4.15.0
WSL2, Ubuntuのインストール
WSL2のインストール
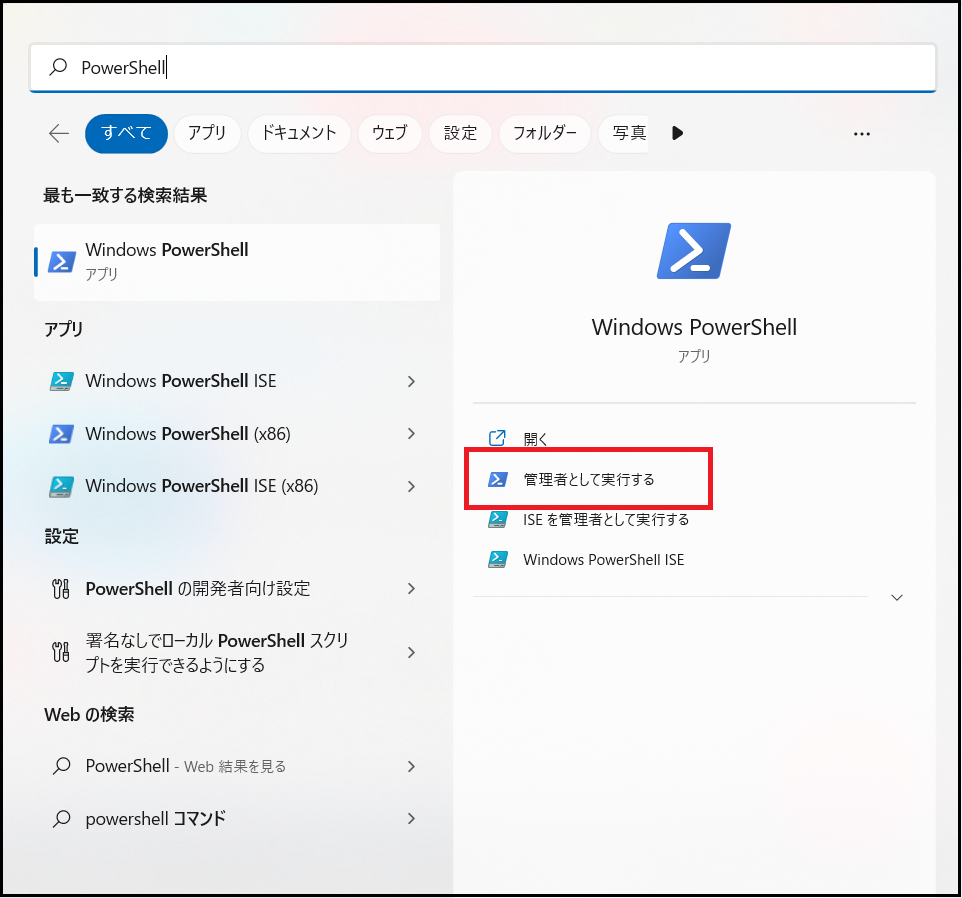
それでは早速、WSL2のインストール方法から紹介します。
WSL2のインストールではPowerShellを使用しますので、Wndows PowerShellの”管理者として実行する”を選択します。
PowerShellが開けたら以下のコマンドを実行します。
wsl --install
その後以下のような表示がでたら、インストールは完了です。表示に出ているように、このコマンド一つで必要な内容をまとめて実行することができます。
PS C:\WINDOWS\system32> wsl --install インストール中: 仮想マシン プラットフォーム 仮想マシン プラットフォーム はインストールされました。 インストール中: Linux 用 Windows サブシステム Linux 用 Windows サブシステム はインストールされました。 ダウンロード中: WSL カーネル インストール中: WSL カーネル WSL カーネル はインストールされました。 ダウンロード中: GUI アプリ サポート インストール中: GUI アプリ サポート GUI アプリ サポート はインストールされました。 ダウンロード中: Ubuntu 要求された操作は正常に終了しました。変更を有効にするには、システムを再起動する必要があります。 PS C:¥Windows¥system32>
インストールが完了したら、PCを再起動します。
Linuxのディストリビューションを指定する場合は以下のようにコマンドを実行してください。
wsl --install Ubuntu-20.04
Ubuntuの設定
WSL2、Ubuntuのインストールが完了すると、Ubuntuが起動するので、ユーザー名とパスワードの設定をしてください。
設定が終われば、Ubuntuが使用可能な状態になります。
PowerShellでも以下のコマンドを実行することで、以下のようにUbuntuの状態がRunningと表示され、WSL2が有効になっているということが確認できます。
PS C:\WINDOWS\system32> wsl -l -v NAME STATE VERSION Ubuntu-20.04 Running 2 Ubuntu Running 2 PS C:\WINDOWS\system32>
Dockerを利用する手順
Docker Desktop for WIndowsのダウンロード
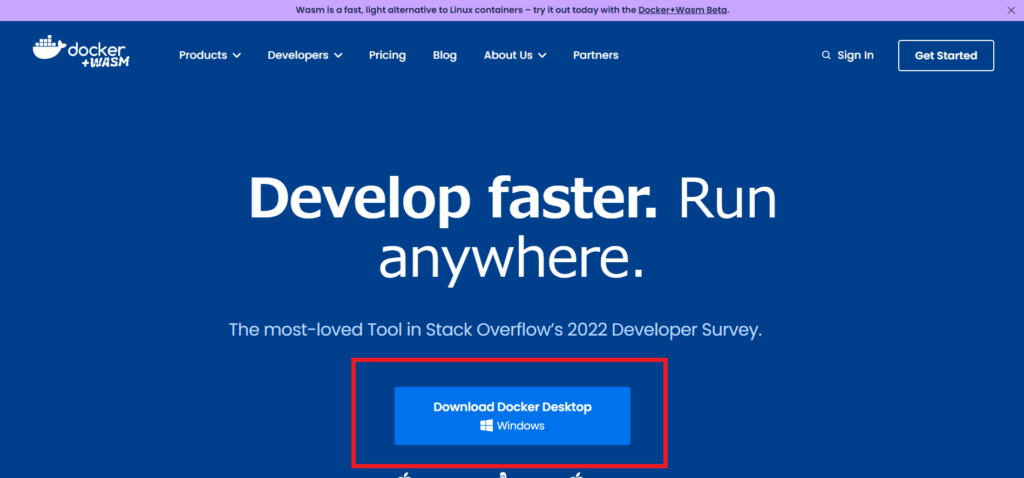
Ubuntuの設定まで終わった後は、公式サイトからDocker Desktop for WIndowsをダウンロードします。
Dockerの公式サイトを開くと「Download Docker Desktop Windows」というボタンがあるので、こちらをクリックしてください。
その後インストーラを起動し、画面に従ってインストールを行ってください。
途中の [Configuration]の画面では「Install required Windows components for WSL 2」にチェックがついているか確認してください。もし、されていない場合はチェックしてください。
Docker Desktop for WIndowsの設定
インストールが終了したら、最後にDocker Desktopの設定を確認します。
起動していない場合はDocker Desktopを起動して、右上の歯車マークから設定画面を開いてください。
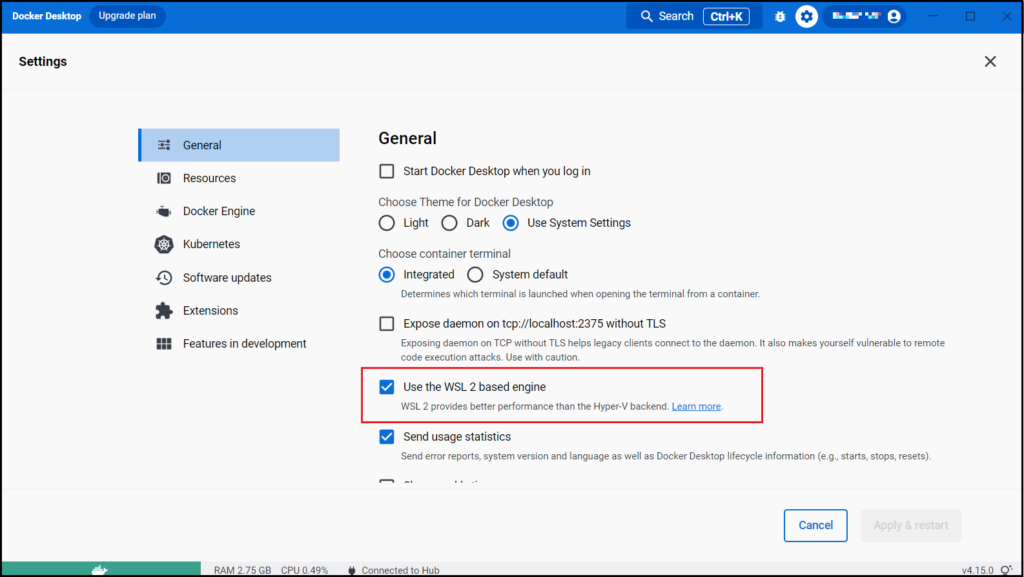
Settingの画面が開けたら、[General]の “Use the WSL 2 based engine” が有効になっていることを確認します。
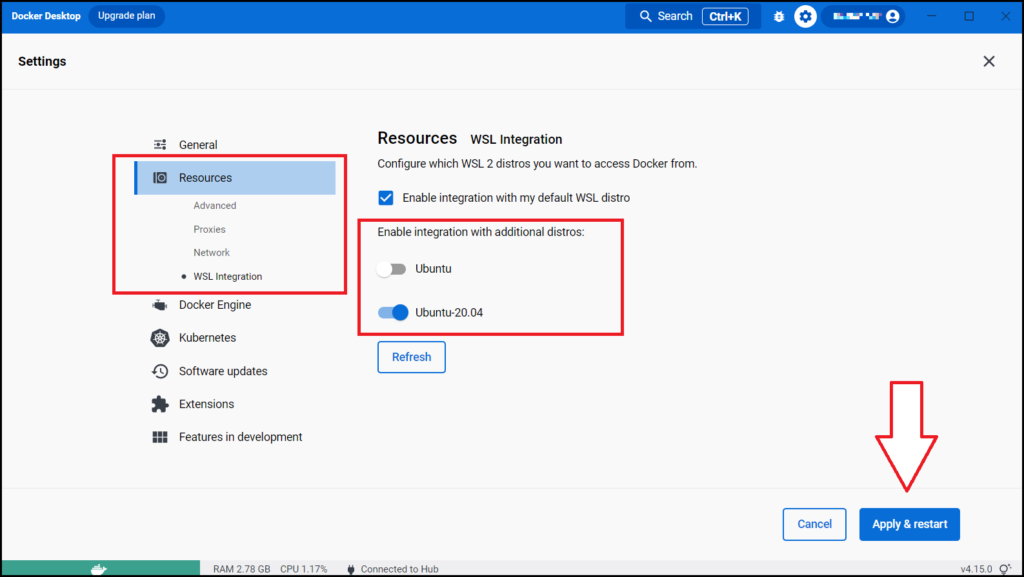
その後、サイドバーから[Resource] > [WSL integration]を選択し、”Enable integration with additional distros:” の下からDockerを使用するものの設定を有効にしてから、右下の「Apply & Restart」ボタンを押します。
今回は例としてUbuntu-20.04を有効にしています。
これで、WSLからDocker Desktopを利用することができるようになりました。
Dockerの動作確認
最後にDockerの動作確認を行います。Docker Desktopの設定でUbuntuが有効になっているので、Ubuntuから動作確認をします。Ubuntuを起動し、以下のコマンドを実行してください。
docker --version
Dockerのバージョンが以下のように表示されれば、動作しています。
Docker version 20.10.21, build baeda1f
まとめ
いかがでしたでしょうか。WSL2を使用することによって、WindowsでもLinuxを簡単に動かせるようになり、Dockerも手軽に試すことができるようになりました。また、今回はUbuntuをインストールして使用していますが、その他のディストリビューションを利用することもできますので、目的に合わせて色々試してみてください。
【Postman】FirebaseにHTTP Requestを送る方法
BtoC, Firebase, PC, Postman, SNS, ツール, 紹介
WebAPI開発やWebAPIのテストを行う際に役に立つツールとして「Postman」があります。Postmanはウェブの世界では広く普及しており、Webアプリケーションの開発に携わっていると、使ったことがあるという人も多いと思いますが、中には初めて聞くという人も多いと思います。
Postmanを使うことで、今までコマンドを使って行っていたことが容易にできるようになり、今後のWebAPI開発やテストにおいてはさらに使われる機会も増えると思います。
また、それと同時にWebアプリケーションのバックエンドの処理をするために、「Firebase」を使用しているという人も多いと思いますので、今回はPostmanを使ってFirebaseにHTTP Requestを送信する方法について解説していきたいと思います。
Postmanとは
それではまず、Postmanについて説明したいと思います。
PostmanはWebAPIを開発して使用するためのWebAPIプラットフォームです。これによって簡単にHTTP通信を行うことができます。
また、Postmanにはオンライン上で使用できるWeb版とインストールして使用するApp版が存在しますが、今回はApp版を使用しての解説になります。ただし、Web版とApp版での操作に違いはないので、Web版を使用していただいても構いません。
Firebaseとは
続いてFirebaseについても簡単に説明したいと思います。
FirebaseはGoogle社のクラウドサービスの一つで、モバイルアプリやWebアプリケーションの背後で必要となるサーバ上の機能をまとめて提供しているものになります。
主な機能としては、利用者認証、メッセージの配信、データの保存、簡易なWebサーバ、FaaS(Function as a Service)、NoSQLデータベース、利用状況の記録・解析といったものがあります。
PostmanからFirebaseにリクエストを送る方法
PostmanとFirebaseについて簡単に理解ができたところで、Postmanを使ってFirebaseにリクエストを送る方法を紹介したいと思います。
ただし、全てを紹介するとかなりの時間がかかってしまうので、今回は基本的な機能であるユーザーの作成、ユーザーのログイン、ユーザーの削除の方法について紹介していきたいと思います。
FirebaseのWebAPIキーを取得
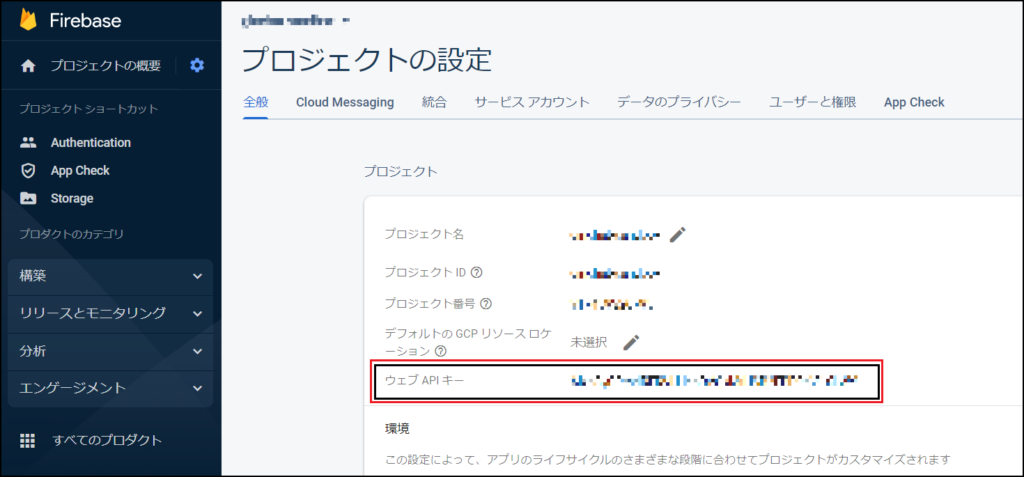
ではまず、FirebaseにアクセスするためのWebAPIキーを取得します。
取得と言ってもFirebaseから、プロジェクトの設定画面を開くと「ウェブ API キー」と表示されているので、それをコピーするだけでOKです。
コレクションとHTTP Requestの作成
続いてPostmanの Collection と HTTP Requestの作成を行います。
Postmanのアプリを立ち上げて、左側の[Create Collection]を選択するか、ワークスペース名の右側にある[new]から”Collection”を選択してください。
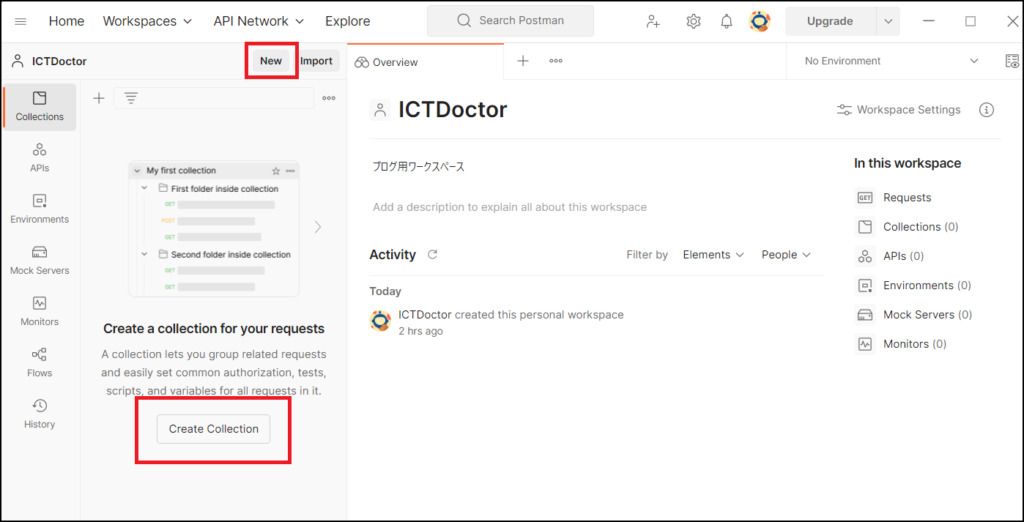
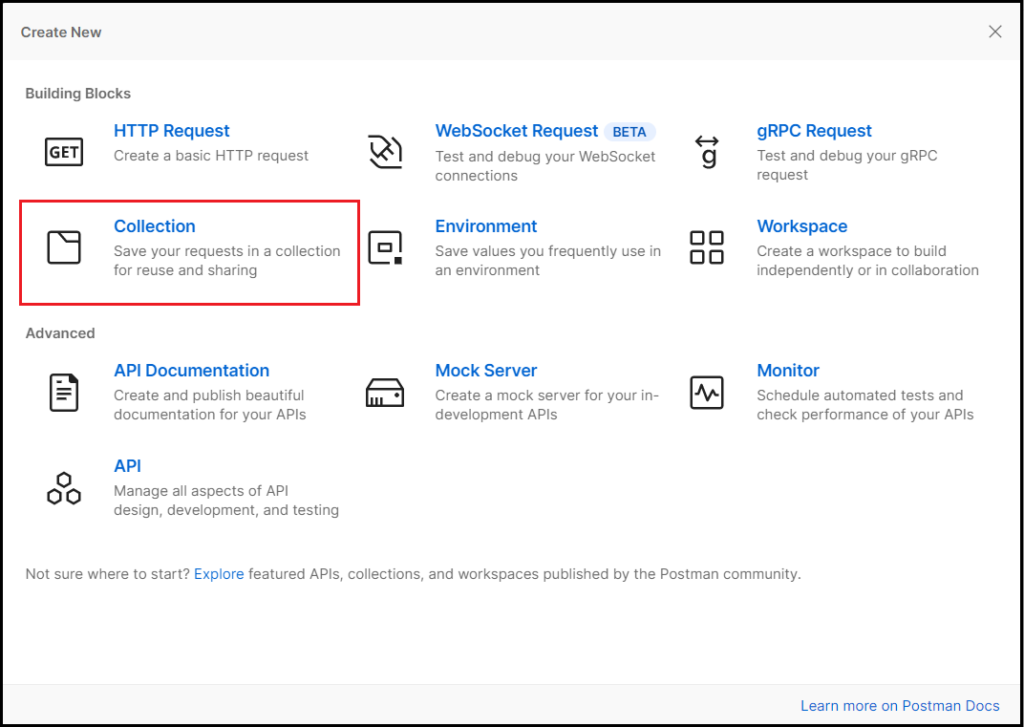
ちなみに、Collection というのは、複数の HTTP Request などをサービス単位等でまとめたもののことです。今回はこの Collection の中にそれぞれの HTTP Request を用意していきます。
Collectionの作成ができたら、HTTP Request の作成に入ります。
左側のCollection名の下にある [Add a request] か、先ほどと同じように [New] のボタンから”HTTP Request”を選択してください。
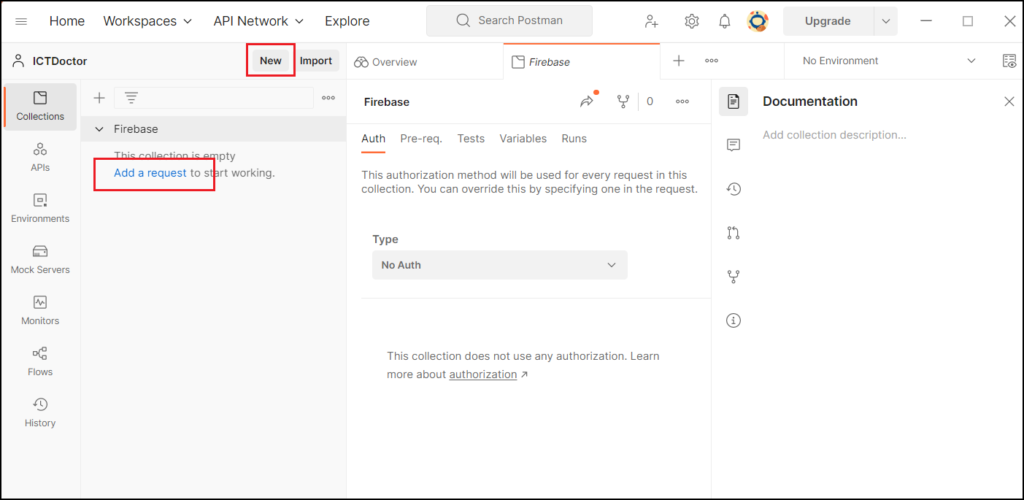
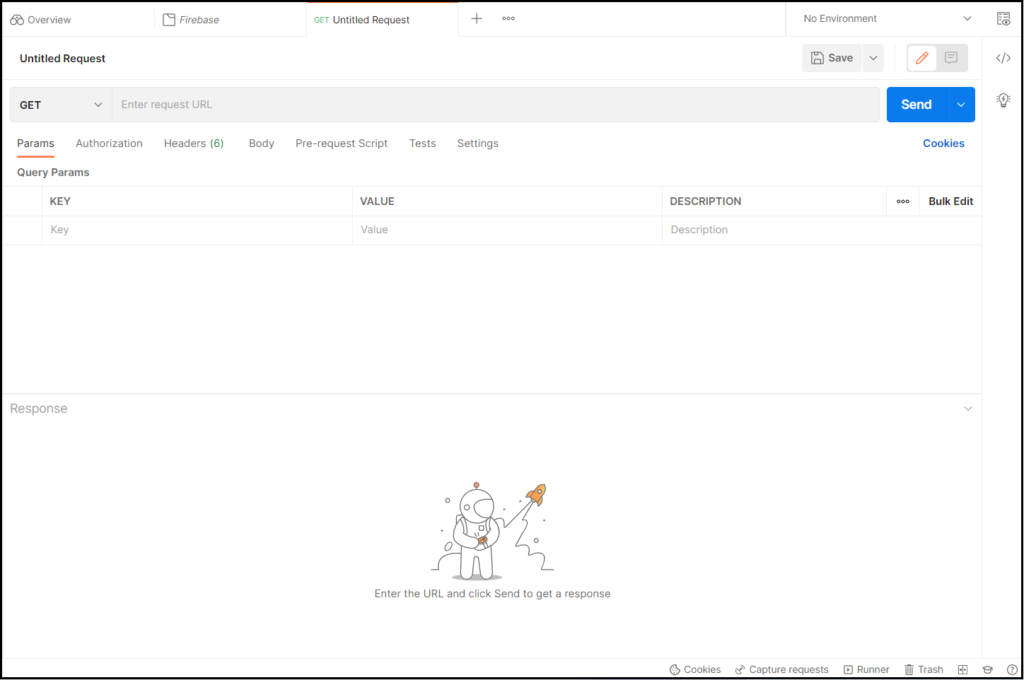
HTTP Requestの画面まで開けたら、準備は完了です。この内容を行いたい処理に合わせて編集していきます。
ユーザーの作成
まずはアプリにユーザーを登録したいと思います。
FirebaseAuthenticationは RestAPI を備えており、そのドキュメントが公式から出ているので、こちらの情報をもとにHTTP Requestの編集を行っていきます。
今回はメールとパスワードを使って登録する方法でユーザーを追加するので、ドキュメントの中の「Sign up with email / password」の内容を確認します。
ここで重要になってくるのが、“Method”, “Content-Type”, “Endpoint”, “Request Body Payload”になりますので、よく確認しておきましょう。
ドキュメントを確認した後はそれをもとにPostmanを編集していきます。
まずは、HTTP RequestのMethodをドキュメントと同じPOSTに、「Enter request URL」に以下の Endpoint の内容を貼り付けてください。
//ユーザー登録のEndpoint https://identitytoolkit.googleapis.com/v1/accounts:signUp?key=[API_KEY]
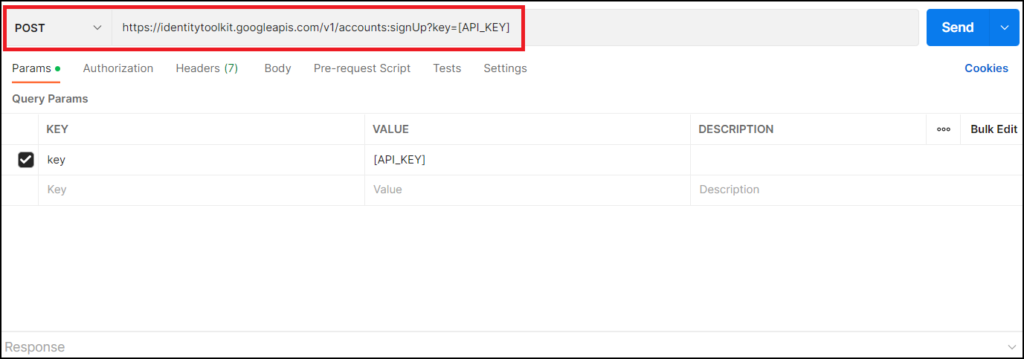
すると、[Params]タブに新しく”key”が追加されますので、対応する[API_KEY]をFirebaseのウェブAPIキーに書き換えてください。上のURLにウェブAPIキーが反映されていれば成功です。
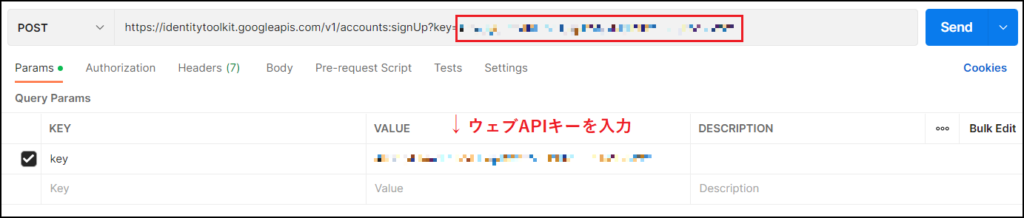
次は実際に登録するメールアドレスやパスワードの情報を送るために、[Body]タブを編集します。
初めは”none”にチェックが入っていると思いますので、[raw] にチェックを入れて一番右の「Text」をドキュメントの “Content-Type” と同じ「JSON」に変更します。
[Body] に記載する内容はドキュメントの “Sample Request” から data-binary を参考に、以下に記載するようにメールアドレスとパスワードを入力すればOKです。
//以下のようにBodyに記載
{"email":"登録したいメールアドレス","password":"登録したいパスワード","returnSecureToken":true}
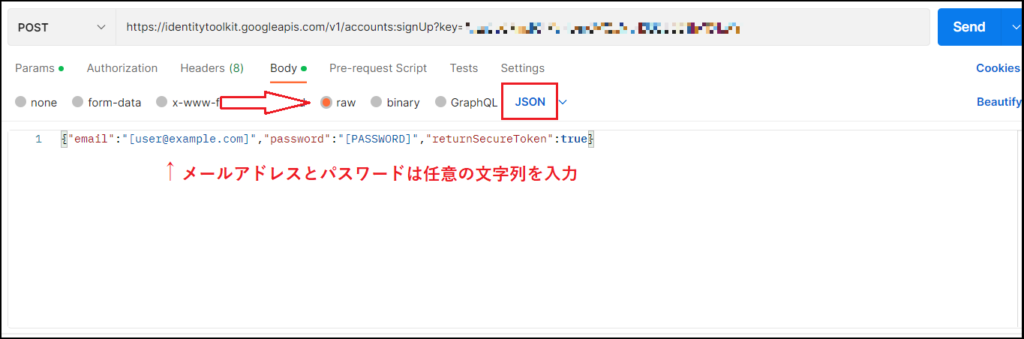
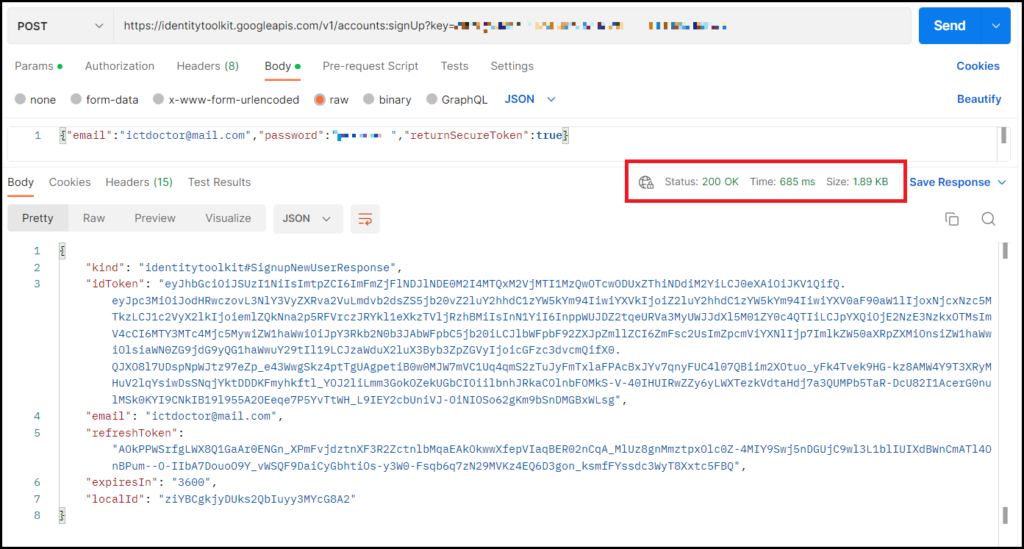
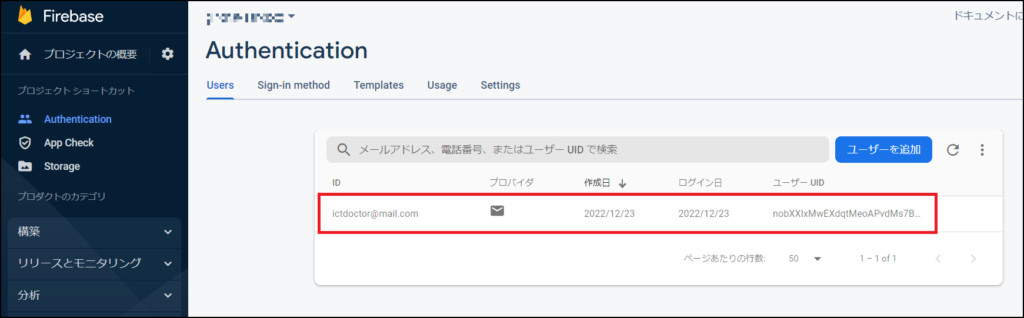
ここまでできたら、最後に右上の「Send」ボタンを押して、200OKのレスポンスが返ってくれば成功です。
Firebaseの[Authentication] > [Users]を見ると先ほど入力したメールアドレスでユーザーが追加されていることを確認できると思います。
ユーザーログイン
ログインの場合もやることは基本的に同じです。
まずは公式ドキュメントの「Sign in with email / password」を確認します。
確認した内容をもとに以下のEndpoint等の入力をします。ここはEndpoint以外はユーザー登録と同じです。
//ユーザーログインのEndpoint https://identitytoolkit.googleapis.com/v1/accounts:signInWithPassword?key=[API_KEY]
続いて[Body]タブを開いて、先ほどと同じように[raw]にチェック、「Text」を「JSON」に変更して、今度は先ほど登録したユーザーのメールアドレスとパスワードを入力します。入力できたら「Send」を押して、レスポンスが返ってくれば成功です。
//以下のようにBodyに記載
{"email":"登録されているメールアドレス","password":"登録されているパスワード","returnSecureToken":true}
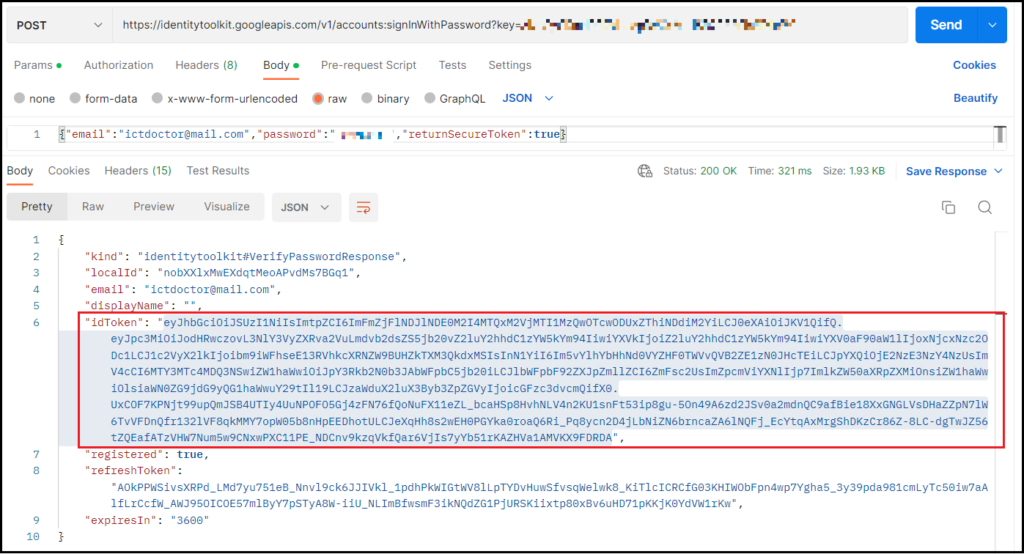
また、ここで返ってきた “idToken” は、この後のユーザー削除や他の操作で必要になる場合があるので、もし入力内容で “idToken” が必要な場合は、対象のユーザーでこの操作を行ってトークンを確認してください。
ユーザーの削除
最後に、今回作成したユーザーのアカウントを削除したいと思います。
公式ドキュメントでは「Delete account」の箇所になります。エンドポイントは以下の通りです。
//ユーザー削除のエンドポイント https://identitytoolkit.googleapis.com/v1/accounts:delete?key=[API_KEY]
今回も、前二つの操作とほとんど変わりありませんが、今回は送信する情報が “idToken” となっています。この “idToken” はユーザー作成時かログイン時のレスポンスで確認することができます。
//以下のようにBodyに記載
{"idToken":"削除したいアカウントのidToken"}
入力が終わって「Send」を押して200 OKのレスポンスが返ってくれば成功です。
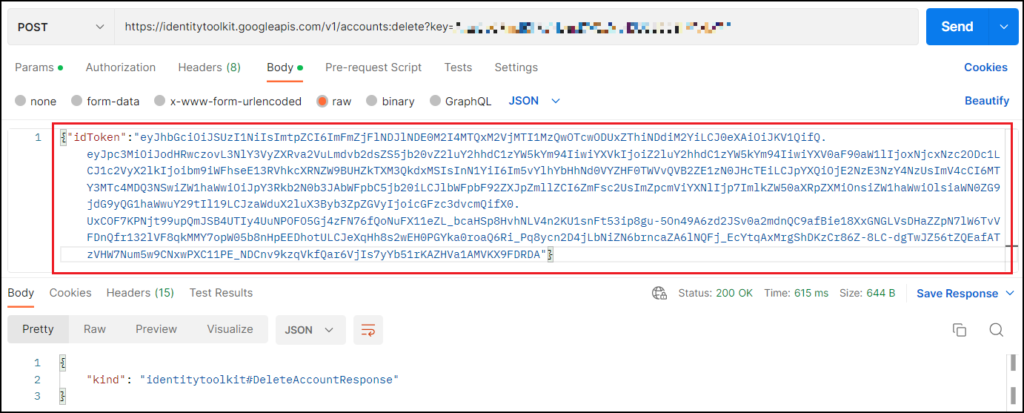
この時にエラーが出た場合はトークンの期限が切れている可能性がありますので、その場合は再度ログインして、新しい”idToken”を入力し直してください。
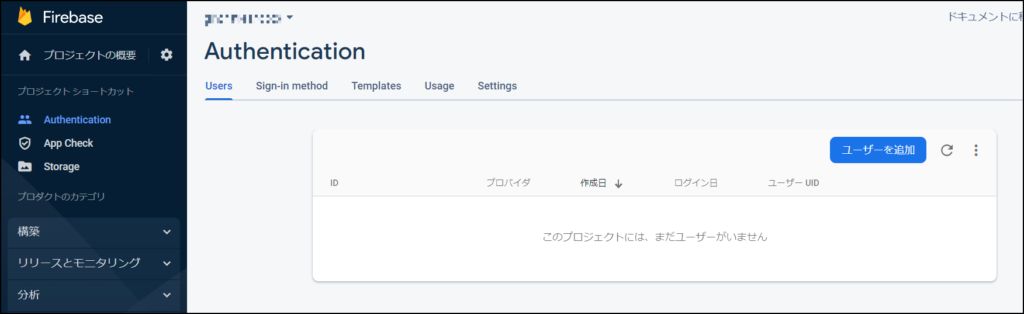
最後にFirebaseの[Users]を確認してユーザーの情報が消えていたら完了です。
まとめ
いかがでしたでしょうか。Postmanを使うことで、curlコマンドなどを使うよりも効率的にリクエストを送ることが可能になります。また、表示も複雑というわけではないので、視覚的にも扱いやすいというメリットもあります。
これからも、使える機会は増えていくと思いますので、これを機会にぜひPostmanを使ってみてください。
GitHubとは?Gitのコマンドと合わせて紹介!
BtoC, Git, PC, Windows, ツール, 紹介
前回、Gitの使い方について解説をしました。それによって、Gitがどういうものか少なからず理解していただけたと思います。しかし、前回のブログの中で説明したように、あの内容はローカルリポジトリという、個々人のマシン上にあるリポジトリの使い方のみの説明であり、Gitを使う上ではそれに加えてリモートリポジトリに関連したGitの使い方や、GitHubについても知る必要があります。
そこで今回は、Gitの使い方とGitHubについて解説していきたいと思います。
GitHubとは
ではまずGitHubについて紹介します。GitHubはGitについて調べると必ずと言っていいほど目にする言葉で、どういったものかある程度理解していたり、名前だけは知っているという方も多いと思います。
ではそのGitHubが何かというと、Gitの仕組みを利用して世界中の人々が自分の作品を保存、公開でき、リモートリポジトリとしての活用や、チーム開発のための機能を提供するWEBサービスの名称です。
リモートリポジトリとは
前回の内容と被ってしまいますが、リモートリポジトリについても簡単に復習します。
そもそも、リポジトリとはバージョン管理によって管理される管理されるファイルと履歴情報を補完する領域のことです。
まずは個々人のマシン上のリポジトリで作業を行い、その後ネットワーク先のサーバー上などにあるリポジトリに集約します。この集約先になっているのがリモートリポジトリになります。
ローカルリポジトリだけでは、一人の作業内容しか保存できないため、複数人で作業するとなると、必ずこのリモートリポジトリが関わってきます。
リモートリポジトリ関連のGitの使い方
前回の使い方では、ローカルリポジトリ内だけでも使えるコマンドについて説明しましたが、最初に説明したように、Gitにおいてはリモートリポジトリも重要な要素であるため、今回はリモートリポジトリに関連した内容を紹介します。
リモートリポジトリの作成
まずは、リモートリポジトリの作成を行います。コマンドを使って作成することも可能ではありますが、今回はGitHubを使った作成方法を紹介します。
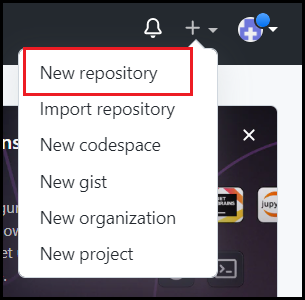
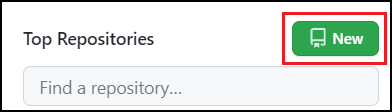
まず、GitHubのダッシュボードのページ右上の「+」マークから「New repository」を選択するか、ページ左側「Top Repositories」の「New」を選択します。
選択後は作成するリポジトリの内容について選択する画面が出てきます。
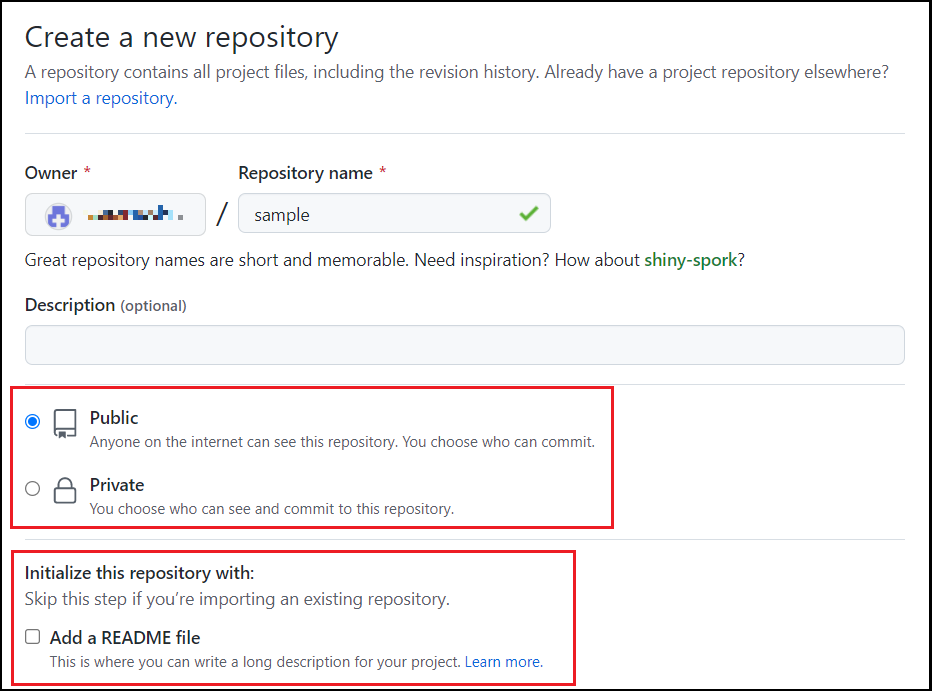
「Repository name」は作成するリポジトリの名前を入力します。(画像ではsample)
次にリポジトリの種類として「Public」か「Private」のどちらかを選択します。「Public」の場合は、他のユーザーがソースコードなどを閲覧することができ、「Private」の場合は非公開となります。
「Initialize this repository with a README」はリポジトリの説明や使い方を記述するREADMEファイルを事前に作成したい場合にチェックします。
その後の「.gitignore」や「license」は None を選択で問題ありません。
すべて入力が終わったら「Create repository」を押して、リモートリポジトリの作成は完了です。
リモートリポジトリが作成できたら、Gitで使うコマンドについても紹介していきます。
git remote
git remote はローカルリポジトリで指定するリモートリポジトリの追加や削除を行うコマンドです。
以下の例のように、GitHubで作成したリモートリポジトリを指定することができます。
$ git remote add origin https://github.com/(自分のアカウント名)/(リポジトリ名).git
git push
git push はローカルリポジトリの内容をリモートリポジトリに反映させるコマンドです。
より正確に言うと、ローカルの現在のブランチをリモートの指定したブランチに反映させるコマンドであり、リモートのブランチを指定する必要があります。ただ、例のように 「-u」を付けるとローカルとリモートのブランチを紐づけることができるので、次回からは git push だけで実行可能にすることもできます。
また、コマンドを実行する際にはGitHubのアカウント名とパスワードが求められますので、間違えないように注意しましょう。
$ git push -u origin main Username for 'https://github.com': アカウント名 Password for 'https://〇〇@github.com': パスワード
git clone
git clone はリモートリポジトリをローカルリポジトリにコピーするためのコマンドです。
前回紹介した git init がリポジトリを新しく作成するのに対して、こちらは既にあるリポジトリを使うという違いがあります。
$ git clone https://github.com/アカウント名/リモートリポジトリ名 Cloning into 'リポジトリ名'... remote: Enumerating objects: 3, done. remote: Counting objects: 100% (3/3), done. remote: Total 3 (delta 0), reused 0 (delta 0), pack-reused 0 Receiving objects: 100% (3/3), done.
git fetch
git fetch はリモートリポジトリの情報をローカルリポジトリに持ってくるためのコマンドです。ただし、持ってくるのは更新情報だけであり、これだけではワーキングディレクトリのファイルに変化はありません。後述する git merge を使うことで、ワーキングディレクトリのファイルを更新することができます。
$ git fetch remote: Enumerating objects: 3, done. remote: Counting objects: 100% (3/3), done. remote: Total 3 (delta 0), reused 0 (delta 0), pack-reused 0 Unpacking objects: 100% (3/3), 587 bytes | 48.00 KiB/s, done. From リポジトリ名 * [new branch] main -> origin/main
git merge
git merge は特定のブランチやリビジョンを、現在のブランチに取り込むコマンドです。
これによって、fetchで持ってきた情報を使って、ローカルを更新することができます。
ちなみに、個人開発でもブランチで作業していた内容を統合する際にはmergeコマンドを使うことになります。
$ git merge origin/main Updating d66e548..e117b19 # 更新内容 Fast-forward profile.md | 1 + 1 file changed, 1 insertion(+)
git rebase
git rebase はmergeと同じように、他のブランチのリビジョンを取り込むコマンドです。
mergeと異なる点としては、取り込んだブランチがベースとなって、自ブランチの差分リビジョンを後ろに付け替えるという点になります。
では、どちらを使うのが良いのか?と疑問に思うかもしれませんが、merge をした場合に生成される「マージリビジョン」がGit管理を複雑にさせるということで、現在は rebase を使う方が一般的となっています。
# リベースで「main」ブランチを取り込む $ git rebase main First, rewinding head to replay your work on top of it... Applying: Add リベース用ファイル
git pull
git pull は先述した git fetch と git merge をまとめて実行できるコマンドです。
わざわざコマンドを分ける必要がないときはこのコマンドを利用するのがおススメです。
また、「–rebase」オプションを使うことで、mergeの代わりにrebaseを実行することができます。
# 通常のコマンド $ git pull #rebaseオプション付きのコマンド $ git pull --rebase
リモート追跡ブランチ
gitのコマンドを一通り紹介させていただきましたが、補足内容として「リモート追跡ブランチ」について解説したいと思います。補足とはいっても、Gitを正確に理解するための重要な内容になりますので、ぜひ覚えていってください。
リモート追跡ブランチとは?
一つのプロジェクトから分岐をさせて、本体に影響を与えず開発をすることができる機能がブランチになりますが、Gitではローカルとリモートリポジトリの同じ名前のブランチが直接連携しているわけではありません。
例えば、先ほど紹介したコマンドの中に “git fetch” がありました。その説明として、リモートリポジトリの情報をローカルリポジトリに持ってきていると言いましたが、その情報(コミット履歴)が更新されるのは、作業中のブランチではありません。
その情報はリモートリポジトリの各ブランチと直接連動しているブランチで更新され、そのブランチのことを「リモート追跡ブランチ」と呼びます。
リモート追跡ブランチはリポジトリをクローンした際にローカルリポジトリ上に作成され、リモートリポジトリの状態を表します。
ブランチ名
リモート追跡ブランチは「remotes/リモートレポジトリ名/リモートブランチ名」という名前がついているブランチになります。
例えば “origin” という名前のリモートリポジトリの “main” ブランチがあるとすると「remotes/origin/main」という名前になります。
ただし、リモート追跡ブランチを指定する時は「remotes/」を省略することが可能なので、「origin/main」だけでも問題ありません。
コマンドとの関係
リモート追跡ブランチがどういったものか理解ができたところで、実際にどのように影響しているのかを、コマンドと合わせて紹介します。
git fetch
リモート追跡ブランチとは何かを説明した際に触れましたが、”git fetch” はリモートリポジトリの内容をリモート追跡ブランチに反映するというコマンドになります。
なので、実際に作業をしているローカルのブランチが変化することはありません。
git merge
“git merge” はfetchで更新されたリモート追跡ブランチの内容をローカルのブランチに反映するコマンドになります。
コマンド紹介の例でも「$ git merge origin/main」のように、冒頭を省略した形でリモート追跡ブランチを指定しています。
git pull
“git pull” は fetch と merge をまとめて行っているものなので、処理の途中でリモート追跡ブランチを経由しているという形になります。
git push
“git push” では、ローカルブランチの内容をリモートブランチだけでなく、リモート追跡ブランチにも反映します。変更した内容が、「origin/main」にも影響を与えるので注意してください。
まとめ
いかがでしたでしょうか。チームで開発を行うとなった時には必ず、このリモートリポジトリやGitHubが関わってきますので、使い方はもちろん、Gitがどういう仕組みなのかを理解しておくと大変役に立つと思いますので、今回の内容はぜひ覚えていってください!
Gitとは?基本的な使い方の紹介
今やエンジニアにとって必須になったGitですが、今まで使ってこなかった人や、エンジニアとしての勉強を始めたばかりの人にとっては、「どういったものか分からない」、「なんとなく理解はできたけど、使い方がよく分かっていない」ということもあると思います。
そこで今回は、Gitの使い方に関して詳しく解説していきたいと思います。
Gitとは
まずGitとは何かについて説明する前に、「バージョン管理」について説明します。
バージョン管理とはソースコードを始めとしたファイルの変更履歴(バージョン)を管理することです。変更された情報を管理することで、過去の変更箇所の確認、特定時点の内容に戻すといったことが可能になります。
そしてそのバージョン管理を行うためのシステムの一つがGitになります。
バージョン管理システムは他にもありますが、Gitは「分散型」のバージョン管理システムであり、個々人のマシン上にリポジトリを作成して開発を行うことができるという特徴があります。
リポジトリとは
バージョン管理によって管理されるファイルと履歴情報を補完する領域を、リポジトリと呼びます。Gitでは、まず個々人のマシン上にあるリポジトリ(ローカルリポジトリ)上で作業を行い、その後に作業内容をサーバー上などのリポジトリ(リモートリポジトリ)に集約して開発を進めていきます。
今回の内容ではローカルリポジトリ上での操作を紹介しています。
Gitを使った開発ではこの区別が重要になるので、こちらもぜひ覚えておいてください。
Gitの使い方
現在ではGitをGUIツールを使って管理することもできますが、GUIツールがない場合やサーバーに入って作業する際など、そういったツールが使えない場合もあります。
そこで、今回は標準で使えるgitコマンドの使い方を紹介します。また、いきなりたくさんのコマンドを説明しても分かりづらくなってしまうので、基本的なコマンドをピックアップして紹介します。
Gitの初期設定
まずはGitをインストールし、その後以下のコマンドでGitの初期設定を行います。
$ git config --global user.name ユーザー名 $ git config --global user.email メールアドレス
git init
プロジェクトをGitで管理する場合は、まずそのプロジェクトのディレクトリに移動してgit initコマンドで初期化をします。
$ mkdir git-tutorial && cd git-tutorial $ git init
今回は例として git-tutorial というフォルダを作成し、そこでgit initを使いローカルリポジトリの作成をしています。
git add
初期化しただけの状態では、どのファイルもGitの管理下にないので、まずはバージョン管理をしたいファイルをgit addを使ってインデックスに登録します。
$ git add Hello.txt
git commit
git addで登録した後は、git commitコマンドで変更内容をコミットします。
コミットとは、ファイルの変更内容をローカルリポジトリに残すことで、変更内容などを記述した「コミットメッセージ」を添えて実行する必要があります。
git commit -m "コミットメッセージ"
git commitのコマンドでは、その後に-m “文字列”という様にコミットメッセージを記述する必要があります。
git status
git statusコマンドではディレクトリやインデックスの状態を確認することができます。
実際の動きを確認するために、先ほどのHello.txt”を編集した状態でgit statusコマンドを打ちます。
$ echo "good morning" > Hello.txt
すると以下のようなメッセージが表示されます。
$ git status
On branch main
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: Hello.txt
Changes not staged for commitと表示されていますが、これはGitの管理下にあるファイルで、差分があるが、git addされておらず、次回コミットの対象になっていないものがあると表示されます。
これをgit addすると、以下のように表示が変わります。
$ git add Hello.txt
$ git status
On branch main
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
modified: Hello.txt
Changes to be committed と表示され、変更後にaddされ、次回コミットの対象に含まれているファイルを表示してくれます。
このように、git status で現在の状態を確認することができます。
git diff
git status はディレクトリやインデックスの状態を確認することができますが、実際に変更などがあった場合に、どこが変更されたのかという差分を確認するには git diffコマンドを使用します。
先ほどの状態でgit diffを使うと以下のように表示されます
$ git diff --cached Hello.txt diff --git a/Hello.txt b/Hello.txt index b016251..b1eb873 100644 --- a/Hello.txt +++ b/Hello.txt @@ -1 +1 @@ -こんにちは +good morning
Hello.txtの中の「こんにちは」という文字列が削除 (-) され、「good morning」という文字列が追加 (+) されたということが分かると思います。
ちなみに例のような git add 済みのファイルは git diff の後に –cached オプションが必要になります。
git log
コミットを行うとそのたびに、バージョンが更新されます。その時点までの記録したコミットログ(バージョン履歴)は git log で以下のように確認することができます。
$ git log
commit 9c4ae3ff92faa7e8818a04535d6ca97189495148 (HEAD -> main)
Author: ユーザー名 <メールアドレス>
Date: Wed Dec 14 13:14:09 2022 +0900
commitします
commit cf9f0b9fa21dd4d6c047d85a8c0b80624a6cd231
Author: ユーザー名 <メールアドレス>
Date: Wed Dec 14 11:54:33 2022 +0900
文字列の追加
commit f51f8800cd3c7d81de7a8e21858ba9e1670bc5d1
Author: ユーザー名 <メールアドレス>
Date: Wed Dec 14 11:41:53 2022 +0900
first commit
コミットを行った日時と、コミットメッセージが表示されます。
commit の後に続いて表示されているのが、コミットハッシュと呼ばれるもので、コミットを一意に識別するためのものになります。
checkout
履歴をさかのぼって、特定のバージョン時点の状態にするには、チェックアウト機能を使います。
先ほどの git log で出てきた表示に(HEAD -> main)と記載されているものがありましたが、HEADというのが、現在参照しているバージョンで、mainとあるのがブランチ名になります。
ここから特定のバージョンに移動する際には git checkout コマンドを使います。checkeout の後には該当のコミットハッシュを入力します。
$ git checkout f51f8800cd3c7d81de7a8e21858ba9e1670bc5d1
$ git log
commit f51f8800cd3c7d81de7a8e21858ba9e1670bc5d1 (HEAD)
Author: ユーザー名 <メールアドレス>
Date: Wed Dec 14 11:41:53 2022 +0900
first commit
checkout をした後にlogを確認すると該当のバージョンにHEADの表示が移っているのが分かると思います。
git reset
もし、Git のコマンドを間違えて実行してしまったという場合には、git resetコマンドでその作業をやり直すことができます。
例えば、間違えてgit addしてしまったファイルを取り消す際には “git reset HEAD ファイル名” または “git reset” で一括取り消しをすることができます。
間違えて行ったコミットを取り消す場合は “git reset HEAD” を使って行うことができます。
# addしたファイルの取り消し $ git reset HEAD ファイル名 # addしたファイルの一括取り消し $ git reset # commitの取り消し $ git reset HEAD
まとめ
いかがでしたでしょうか。Gitの使い方を覚えておくと、ソースコードの管理ができたり、チームでの開発も効率的に行うことができるようになります。
Gitの内容に限りませんが、知識として学ぶだけでなく実際に使ってみることで、より理解が深まると思いますので、今回の内容を参考にして皆さんも使ってみてください。
【Confluence】覚えておきたいエディターの使い方
BtoB, Confluence, PC, ツール, 紹介
前回、情報共有ツールであるConfluenceがどういったものなのか、どのような特徴があるのか解説しました。ただし、特徴が分かっていざ使ってみようとしても、使い方をよく分かっていないと、うまく活用できないということがあると思います。
そこで今回は、Confluenceの主な機能である、ページを編集する際に使うエディターの使い方について詳しく解説したいと思います。
ページの作成
エディターを使うにはまず、ページを作成する必要があるので、左のサイドバーからページを作成しましょう。
エディターの使い方
では早速エディターの使い方について説明していきます。
一般的な文章作成ツールでも使われるような機能も画面上部のバーに表示されていますので、そのような機能は感覚的に使うことができると思います。
なので、今回はそのバーに表示されている機能の中で重要なものについて解説していきたいと思います。

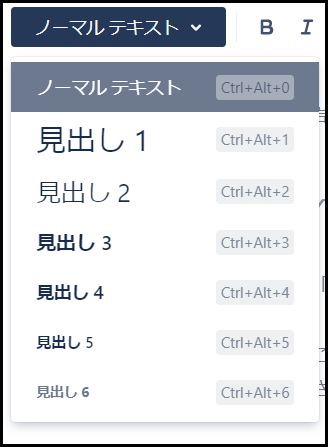
テキストスタイル
こちらの機能も一般的に使われている機能ではあると思いますが、Conflueceではテキストの大きさを、ノーマルテキストと見出し1~6に分けて設定することができます。
これによって内容が見やすくなるのはもちろん、後述の目次機能ではこれをもとに自動で目次を作成してくれます。

アクションアイテム
四角にチェックがついたマークの機能は、アクションアイテムと呼ばれる機能になります。
これは、例えばチーム内でタスクを割り当てるとき等に使う機能です。アクションアイテムでタスクを決めておいて、それが終了したらチェックを付けるという様にして、どういったタスクが残っているか等を分かりやすく確認することができるようになります。

メンション
@の機能は、メンション機能になります。@の後に名前を続けて特定の人をメンションするという機能はConfluenceに限らず、様々なツールで活用されていると思いますが、Confluenceでは同じチームの人にメンションしたい時に使われます。
また、先述のアクションアイテムの画像にあったように、組み合わせて使うことで、このタスクが誰に割り振られたものなのかを分かりやすくするといったことができます。
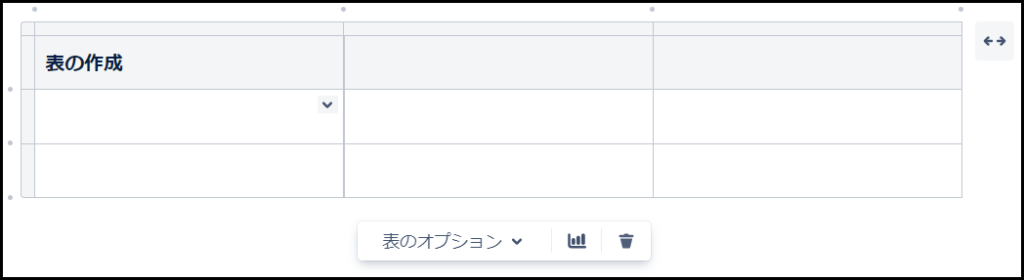
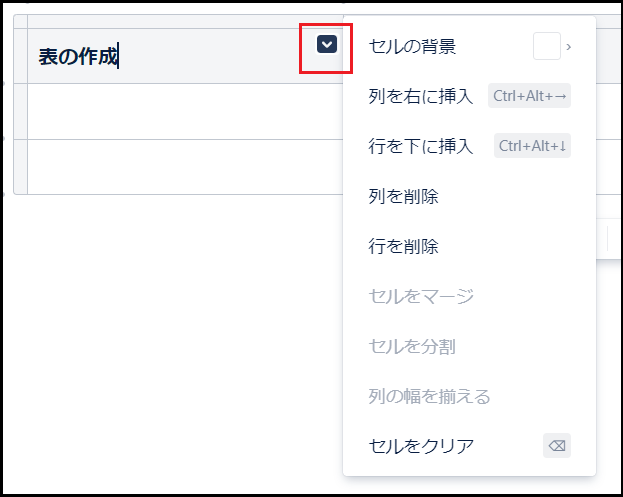
表
四角の中に十字が入ったマークは、表(テーブル)を作成する機能です。
ボタン一つで表を作成することができ、列や行を増やしたり減らしたりといった基本的な操作も簡単に行うことができます。
レイアウト
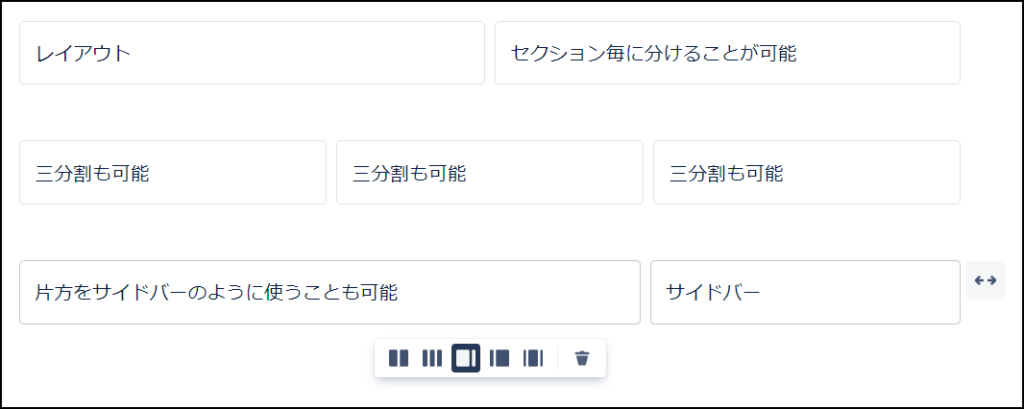
黒い長方形が二つ並んだマークはレイアウトと呼ばれる機能になります。
これによって、ページを「セクション」というひとかたまりで管理できるようになり、ブログのようにレイアウトを調整することができるようになります。
セクションの形はレイアウトの下の表示から選択することができ、場合によって使い分けることも可能です。
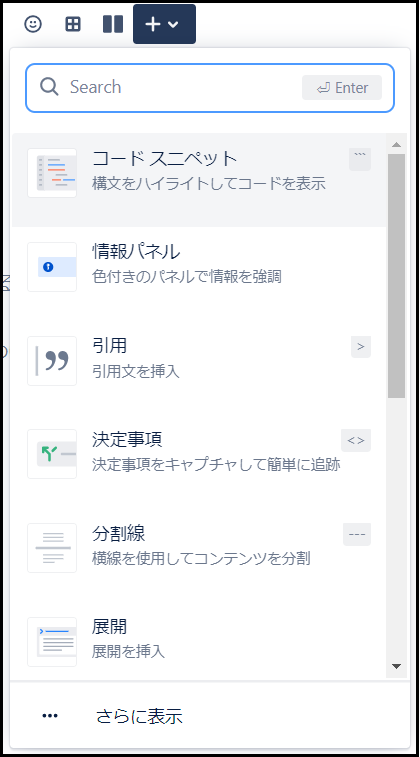
+ボタン
画面の+ボタンからは、上のバーに表示しきれない、様々な機能を挿入することができます。
その機能の数は膨大で、拡張することによりさらに増えていくこともあります。
ただし、この機能すべてが頻繁に使われるものというわけではないので、この中から一部抜粋して紹介していきます。
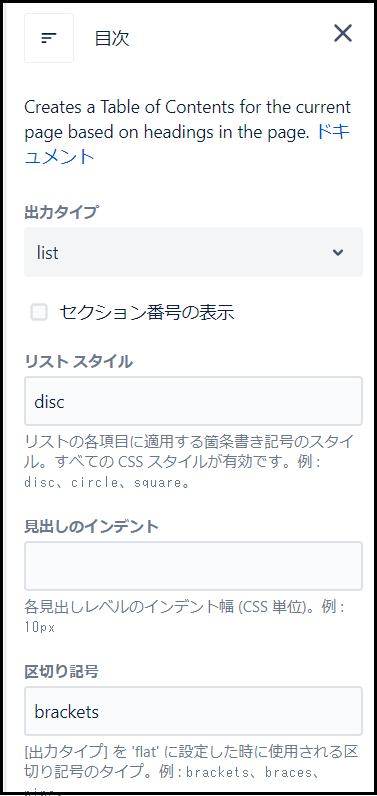
目次
目次はその名の通り、ページ内の見出しをもとに目次を作成してくれる機能になります。
見出しの大きさに合わせてインデントも調整してくれるので、わざわざ自分で調整する必要などがありません。
ただ、縦に並べるか横に並べるか、どこまでの見出しを目次で表示するか等の細かい調整も可能ですので、場合によって調整すると、より見やすい目次を作ることができます。
注意点として、編集画面では目次がどのように表示されるか確認できないので、まずはプレビューで表示を確認してから公開するようにしましょう。

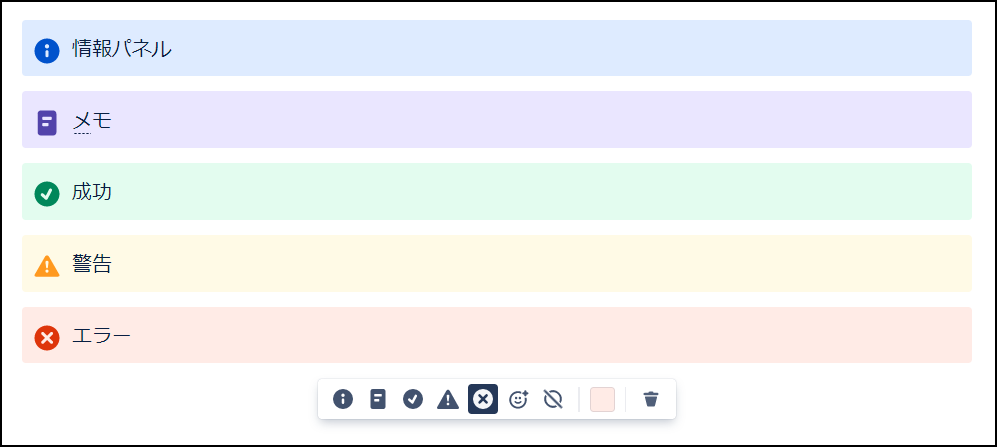
情報パネル
情報パネルは、テキストに対してマークや色などを付けて、注意を引くことができる機能です。
画像のように、あらかじめマークが用意されており、テキストの内容に合わせて使うマークを選択することで、より確認しやすくなります。
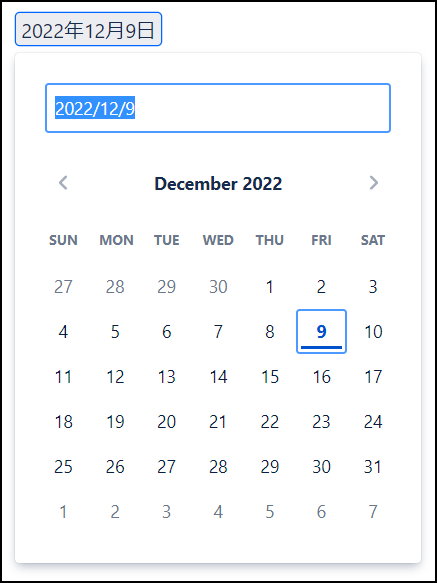
カレンダー
カレンダーはその名の通り、日付を入力することができる機能です。
カレンダーの表示が出てくるので、わざわざ入力しなくてもクリックするだけで日付を入力することができます。
スラッシュコマンド
最後にスラッシュコマンドについて説明します。
スラッシュコマンドとはショートカットキーのようなもので、「/」を入力することで、Confluenceの機能をすぐに挿入することのできる機能です。
これを使いこなせるようになれば、マウスで選択する手間が減り、作業効率が格段に上がります。
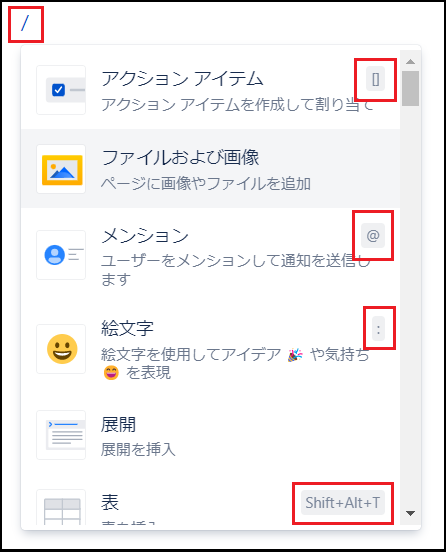
また、機能の表示の右側にある記号は、「/」と組み合わせることで、その機能を挿入できるものになります。
例えば「/@」と入力することで、マウスで選択しなくてもメンション機能が挿入されます。
よく使う機能については、このショートカットはぜひ覚えておきましょう。
まとめ
いかがでしたでしょうか。エディターで可能なことはたくさんありますので、一度で覚えきるのは難しい思います。なので、まずは主要な使い方を覚えてから必要に応じて色々試してみると、使いやすい便利な機能が見つかったりすると思いますので、ぜひ今回の内容を参考にしてみてください。
Confluenceとは?その特徴を詳しく解説
BtoB, Confluence, PC, ツール, 紹介
社内の情報管理を適切に行うために、社内wikiやナレッジ管理ツールなどと呼ばれるツールを導入しようと考えている企業は多いと思います。
ただし、現在ではそれらのツールも多種多様であり、どのツールがどういった機能を持っているのかが気になっている方も多いのではないでしょうか
そこで今回は、その中でもAtlassian社が提供しているConfluenceについて、どういったツールなのかを詳しく解説していきたいと思います。
社内wiki、ナレッジ管理ツールとは
まずは、最初に出てきた社内wikiやナレッジ管理ツールという言葉について簡単に説明したいと思います。
情報共有ということだったら、社内チャットでやり取りをしたり、プロジェクト共有ツールを使って行っているという企業もあるかもしれません。
しかし、チャットでは気軽にやり取りできるという利点があるものの、情報がすぐ流れて行ってしまうため、長期的に利用される情報を共有することには向いておらず、プロジェクト共有ツールもプロジェクト毎の内容を管理するものになりますので、長期的、汎用的に利用される情報の共有をするには少し不便です。
そこで、そういった長期的に使われるマニュアルや議事録、業務ノウハウといった情報を管理するために使用されるのが、今回紹介するConfluenceのような社内wikiやナレッジ管理ツールと呼ばれるツールになります。
Confluenceとは
ConfluenceはオーストラリアのAtlassian社が提供する、チームのナレッジやノウハウの一元管理ができる情報共有ツールです。
また、情報管理だけでなく、マニュアルや議事録をドキュメント形式で作成することも可能です。
Confluenceの特徴
では、Confluenceの特徴について説明します。
簡単に記事を作成できる
Confluenceの特徴として、様々な種類の記事を簡単に作成できるという点があります。
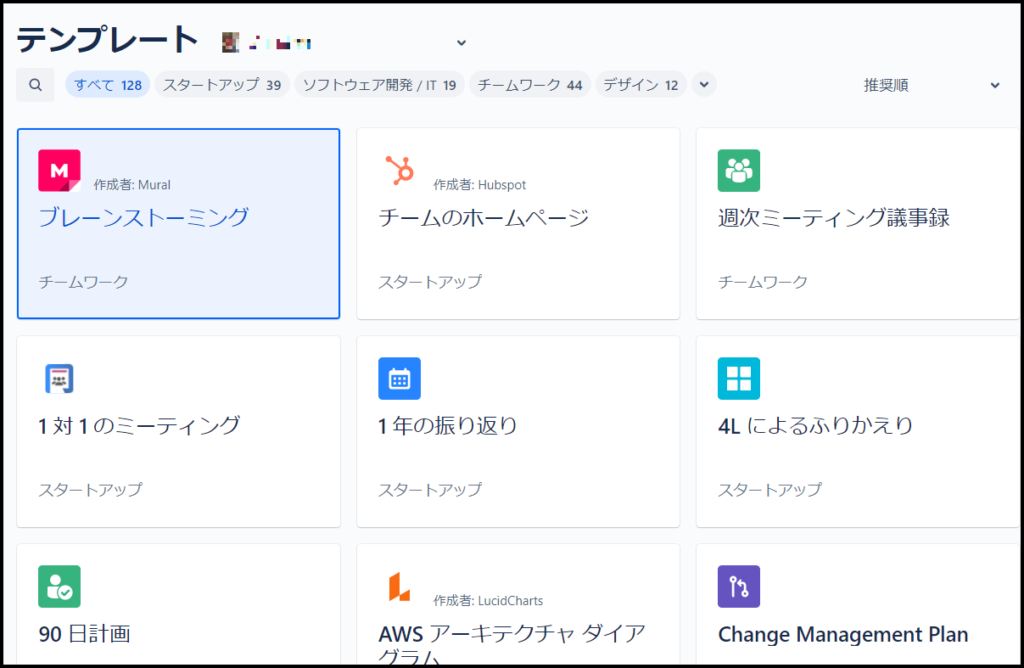
一から記事を作っていくとなると、その内容によってフォーマットを変えたりする必要があると思いますが、Confluenceには会議向けの議事録、企画書、マーケティング、製品要件など豊富な種類のテンプレートが用意されています。
階層構造でコンテンツを管理できる
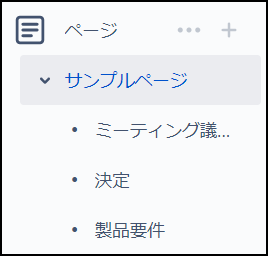
Confluenceでは、基本的にスペースという項目を作ってから、その中にページという単位でコンテンツを作成することができます。ページの下にさらにページを作るということも可能であり、トピック毎に見やすくまとめることができます。
メインメニューでそれぞれの階層構造を確認したり、作ったページを移動したりすることもできるため、簡単に管理ができるようになっています。
コメント機能が充実している
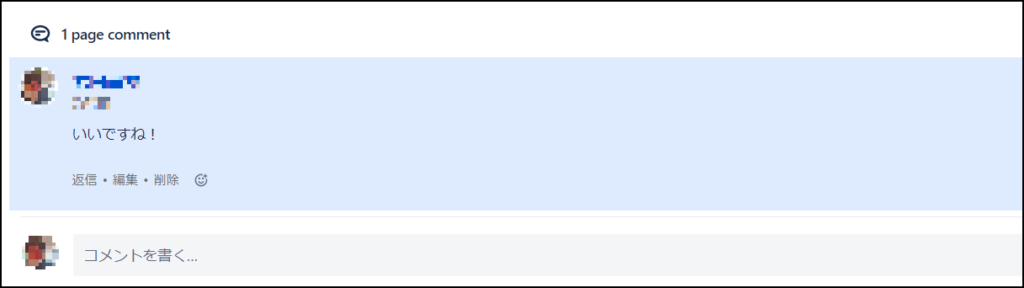
Confluenceで作成した記事にはコメントを入力することができます。それによって、記事の内容についてのやり取りをすることも可能です。記事全体ではなく、記事の一部にコメントを付ける「インラインコメント」という機能もあるため、より分かりやすくやり取りをすることもできます。
また、「いいね」機能を使ってリアクションのみをするということもできます。
「ウォッチ」で通知を受け取れる
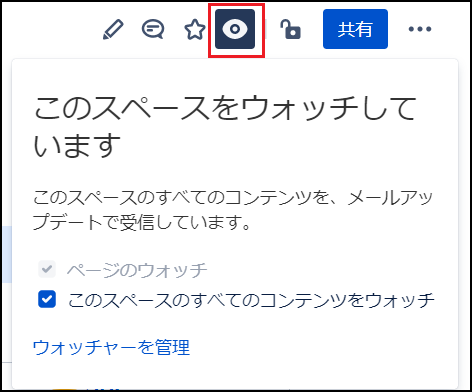
気になるページがある場合は、「ウォッチ」という機能を使うことで、更新があった際にメールで通知を受け取ることができます。これによって、特定の内容について最新情報をすぐに確認することができるようになります。
他アプリケーションと連携できる
Confluenceは同じAtlassian社の製品であるJiraやTrelloだけでなく、GoogleドライブやSlackなどと連携することが可能であり、用途の幅をさらに広げて使うことなども可能です。
その他にも、Confluenceの機能を拡張するマクロなども提供されていますので、Confluenceで使いたい機能を追加するということも可能です。
まとめ
いかがでしたでしょうか。Confluenceを使うことで、社内の情報は格段に管理しやすくなると思います。それによって、必要な書類を探す手間が省けたり、会社全体での情報共有が簡単にできるようになったりと、普段の業務が効率的に行えるようになると思いますので、ぜひ導入を検討してみてはいかがでしょうか。
Android Studioを
日本語で使いたい!
Android, Androidstudio, PC, ツール, 紹介
現在、Androidアプリを開発する際にはAndroid Studioを使っている方が多いと思います。
AndroidStudioはGoogleからも推奨されている総合開発環境であり、これからAndroidアプリを開発したいと考えている方にもおすすめのIDEです。
しかし、使用されているのが英語のため、使うのに少し手間取ってしまうということがあるかもしれません。
英語に慣れるためにも、そのまま使った方が良いと思う方もいるとは思いますが、英語がやっぱり苦手で、日本語で使いたいと考えている方も少なからずいると思います。
そこで今回は、日本語で使いたいという方に向けて、Android Studioを日本語化する方法について解説したいと思います。
また、今回はAndroid Studio Dolphinの解説になりますので、ご注意ください。
バージョン確認
では早速、日本語化の手順を紹介していきたいと思いますが、まずは使っているAndroid Studioのバージョンを確認します。
バージョンを確認する場合はAndroid Studioを開き、画面上部の[Help]から[About]を選択します。

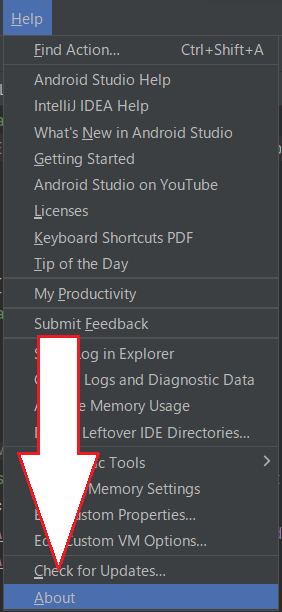
すると、画像のようにAndroid Studioのバージョン情報が表示されます。
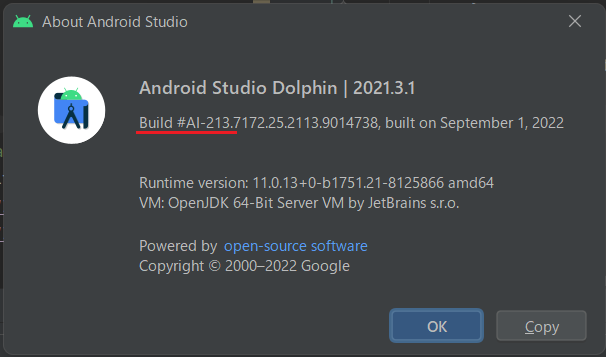
この時に確認していただきたいのが、Build #AI-と書かれた箇所の次の数字です。今回は213…と続いています。
日本語化のPluginをダウンロードする
バージョンの確認ができましたら、日本語化するためのPluginをAndroid Studioに追加していきます。
Android StudioのPlugin MarketplaceにはDolphinに対応したPluginが存在しないため、JetBrains公式の言語パックのjarファイルをPluginとして追加します。
Pluginは以下のサイトから入手できます。
https://plugins.jetbrains.com/plugin/13964-japanese-language-pack——
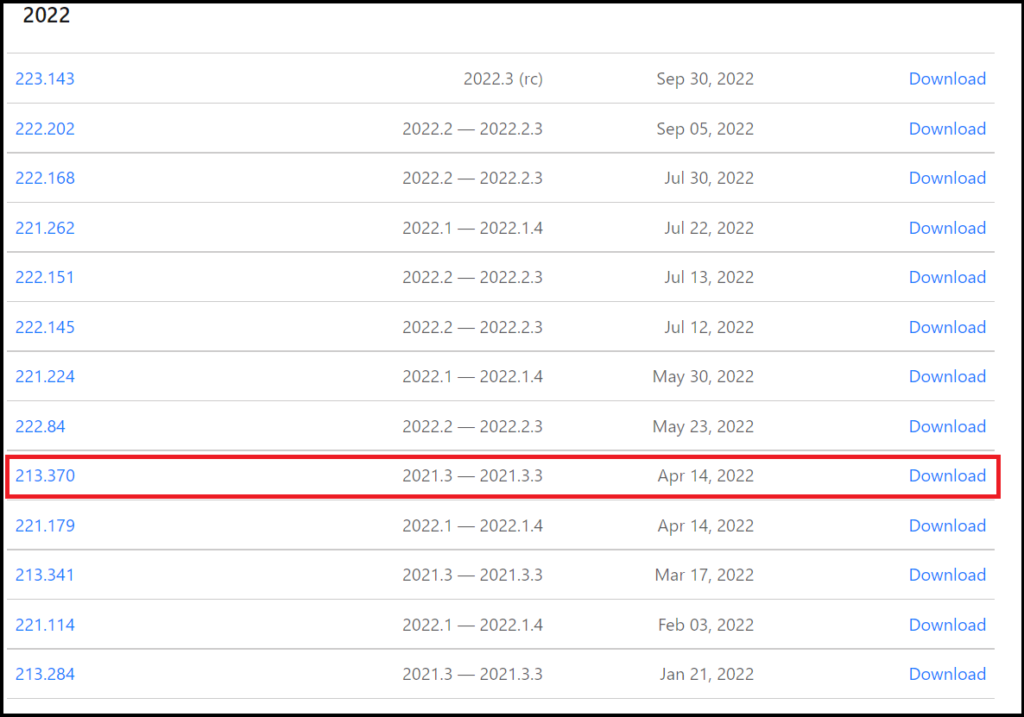
サイトが表示されたらVersionsタブを選択します。

バージョン一覧が表示されたら、その中から自分が使っているAndroid Studioのバージョンと同じものを探します。今回は先ほど確認したようにバージョンが213…だったので、213系の中で最新のもの (213.370) を選択します。
選択すると細かい情報が出てきますので、問題なければダウンロードします。
PluginをAndroid Studioに適用する
日本語化のファイルをダウンロードしたら、Android Studioの最初の画面を開き、左側の「Plugin」を選択します。その後、右上の歯車マークから「Install Plugin from Disk…」を選択します。
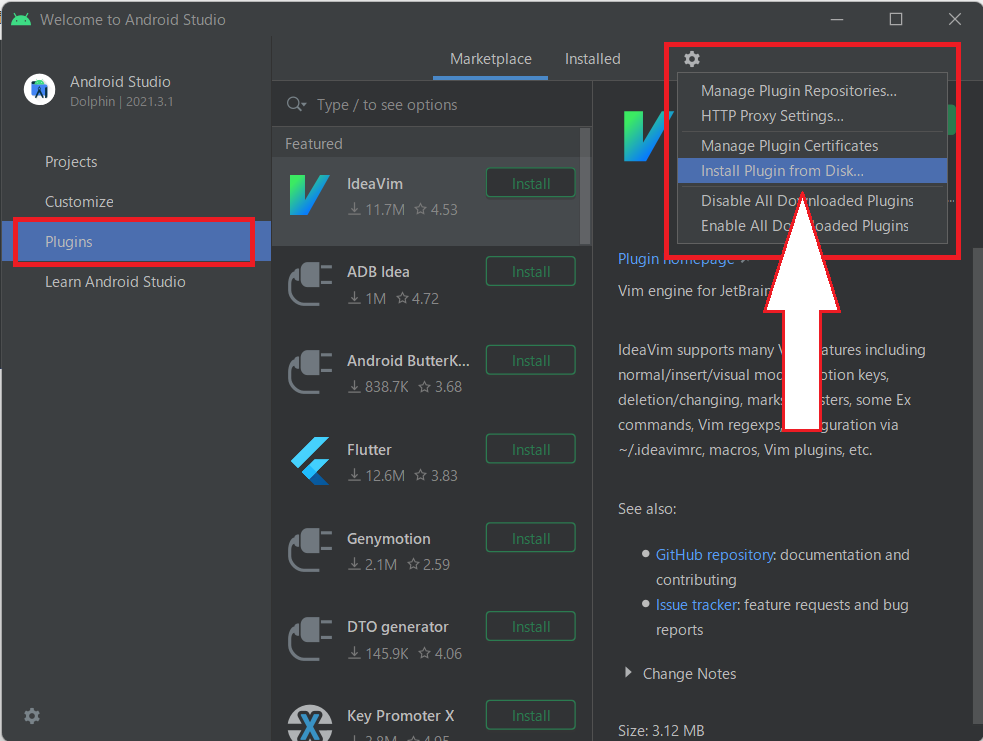
インストールするファイルを選択する画面が出てきますので、先ほどダウンロードしたファイルを選択し、OKを押します。
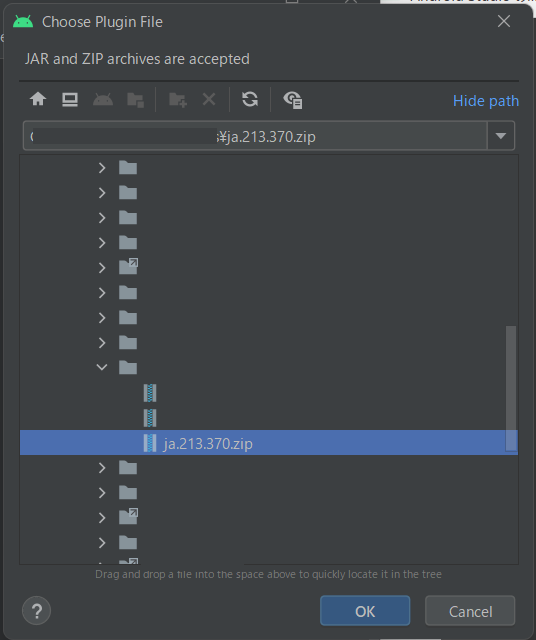
選択したPluginが表示されますので、右上の「Restart IDE」を押して、Android Studioを再起動します。
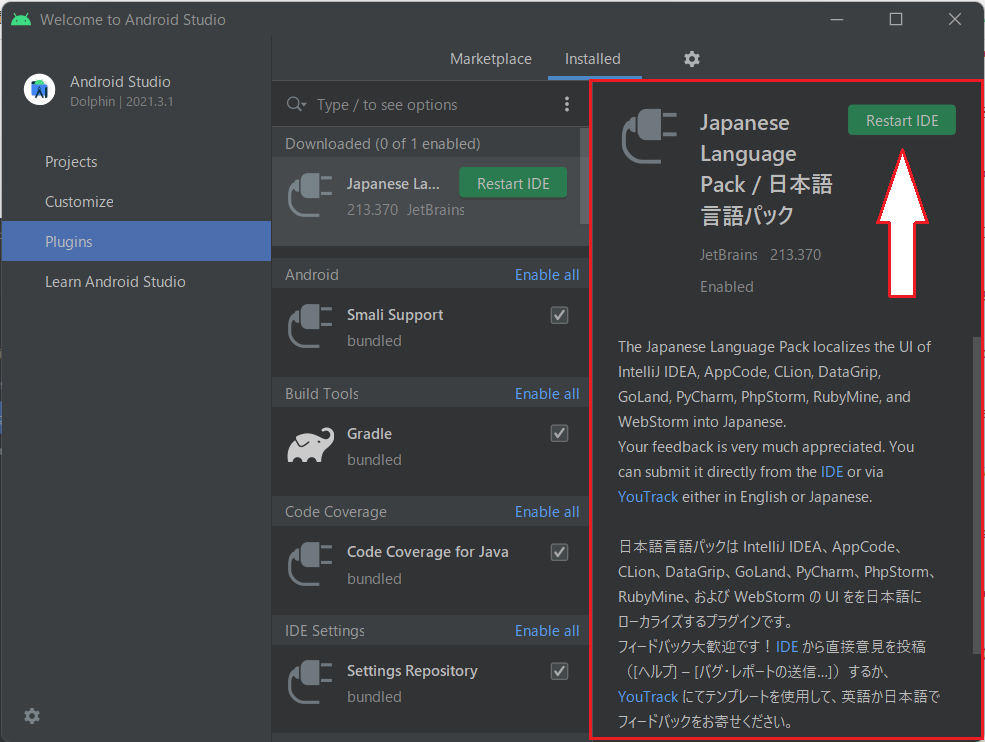
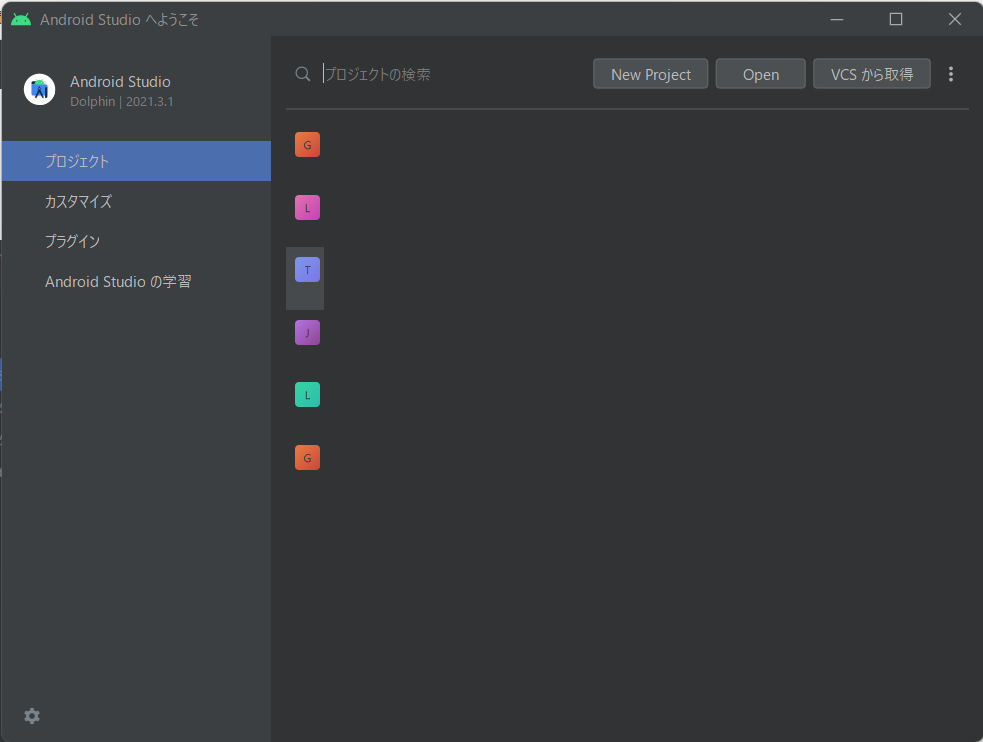
これで日本語化が完了します。
画像のように、英語の表示が日本語に変わっているのが確認できると思います。
まとめ
いかがでしたでしょうか。日本語で表示されるとより細かい設定も簡単にできるようになると思います。もし、英語表示で使いづらく感じるといったようなことがあれば、一度日本語表示にしてみて使ってみると良いかもしれません。
【Android】
Activity,Fragmentの
ライフサイクルを
理解しよう!
Androidアプリの開発ではActivityやFragmentを使ってアプリの画面を実装していくと思います。そして、その際に気を付けなければならないのが、それぞれのライフサイクルです。
ライフサイクルを理解していないままコーディングを行ってしまうと、画面の表示が意図しないものになってしまったり、メモリが増加してしまったり等、予期しない不具合が起こってしまうことがあります。
逆にライフサイクルを正しく理解していれば、アプリの状態に合わせて的確な処理が実装できるようにもなります。
そこで、今回はActivityとFragmentそれぞれのライフサイクルがどのようになっているのかをまとめてみました。
Activity
まずはActivityから解説します。
Activityとは
Activity とは簡単に言えば、「Androidアプリで表示される画面」になります。
普段皆さんが使っているアプリも、起動するとアプリの画面が開いてから操作ができるようになると思います。その時に開く画面そのものがActivityになります。
アプリの中に複数の画面が用意されている場合は、Activityも複数使われます。
Activityのライフサイクル
Activityのライフサイクルを理解するために、まずはこちらの画像をご覧ください。
出典:アクティビティのライフサイクルについて
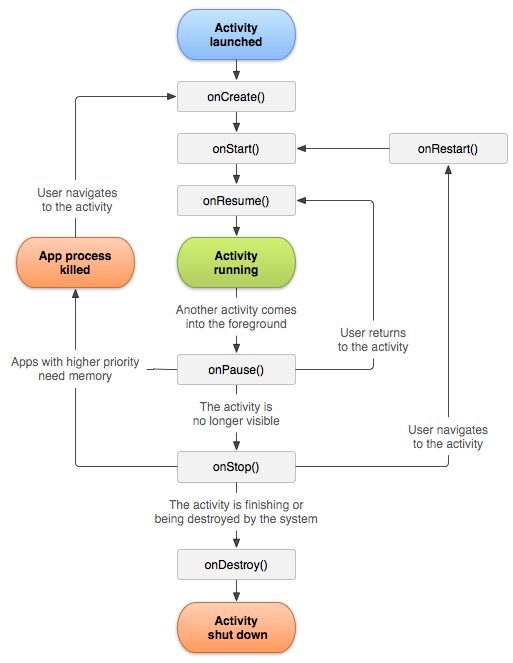
この画像から分かるように、Activityのライフサイクルでは7つのコールバックが提供されています。
それぞれのコールバックについて説明します。
onCreate()
Activityが生成される際、最初に呼ばれます。
このタイミングでViewを作成したり、基本的な設定をする処理を行ったりします。
onStart()
Activityが「開始」の状態になると呼び出されます。
このタイミングでonCreate()で取得したViewへのイベント登録や初期化を行います。
この時点でActivityはフォアグラウンドに移動しますが、まだ操作をすることはできません。
onResume()
Activityがユーザーからの操作を受け付け始める際に呼び出されます。
このタイミングではデータベースからデータを取り出したり、必要な情報をセットしたりするなど、表示や操作ができるようになるために必要な処理が実行されます。
onPause()
アプリがフォアグラウンドでなくなった時や、停止する前に呼び出されます。
この状態はActivityが一時停止している状態であり、続行しない操作を停止したり、続行する操作をバックグラウンドで動くように調整したりします。
onStop()
アプリが完全にバックグラウンドに移動した時に呼び出されます。
この状態ではActivityは非表示になり、停止しています。
ユーザーからアプリが見えていない状態のため、不要なリソースの開放やアニメーションの一時停止といった処理を行います。
onRestart()
Activityが非表示の状態から再度表示される際に呼び出されます。
画像にあるように、この後はonStart()が呼び出されます。
onDestroy()
アプリが終了するなどして、Activityが破棄される前に呼び出されます。
以前のコールバックで解放されていないリソースがここで解放されます。
Fragment
続いてFragmentについて解説します。
Fragmentとは
FragmentとはアプリUIの部品になるビューです。Activityよりも細かい単位でのレイアウトを定義して管理することができ、Activityの子ビューとして構成されます。
Fragment自体はActivityに依存しているわけではないので、複数のActivityから呼び出すことが可能という性質もあります。
Fragmentのライフサイクル
Fragmentのライフサイクルにおいても、まとめられた画像がありますのでご覧ください
出典:フラグメント
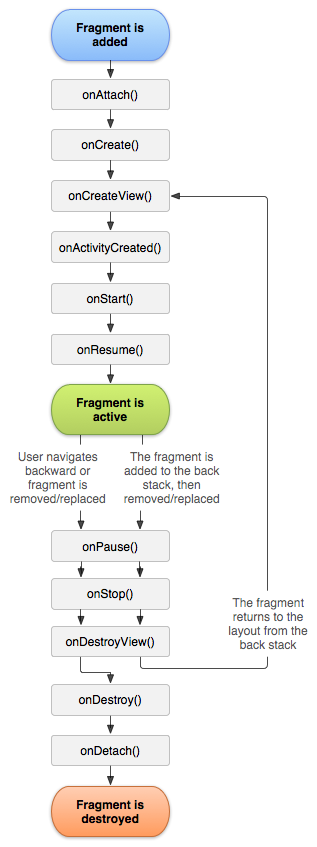
見てわかるように、Fragmentも複数のコールバックが提供されていますので、それぞれ説明します。
onAttach()
FragmentがActivityと関連付けられた時に呼び出されます。
Fragmentにおける最初のメソッドになります。
onCreate()
Fragmentが作成された時に呼び出されます。
この時点でFragmentの初期化が行われます。
onCreateView()
Fragmentに関連付けられたViewを作成する際に呼び出されます。
Fargmentに描画したいViewを返すことで、任意のViewを表示できるようになります。
onActivityCreated()
ActivityのonCreate()が完了した際に呼び出されます。
onStart()
Fragmentがユーザーに見えるようになった時に呼び出されます。
Activityと同様に、この時点ではまだ操作することはできません。
onResume()
Fragmentがユーザーの操作を受け付け始める時に呼び出されます。
このメソッドはActivityと同時に実行されます。
onPause()
Fragmentがフォアグラウンドでなくなった時や、停止する前に呼び出されます。
この時点で保存しておくべき情報が保存されます。
onStop()
Fragmentがバックグラウンドに移動し、ユーザーに表示がされなくなった時に呼び出されます。
この時点では表示はされていないものの、破棄するまでには至っていません。
onDestroyView()
Fargmentに関連付けられたViewが削除された時に呼び出されます。
onDestroy()
Fragment自体が破棄される前に呼び出されます。
こちらはActivityのonDestroy()の前に呼び出されます。
onDetach()
FragmentとActivityの関連付けが解除された時に呼び出されます。
このメソッドもActivityのonDestroy()の前に呼び出されます。
まとめ
いかがでしたでしょうか。一度にすべて覚えるというのは難しいかもしれませんが、ライフサイクルは重要な考え方の一つですので、流れだけでも覚えておくと役に立つと思います。
細かい部分が分からなくなってしまったという時は、今回の記事を見直して一つずつ確認してみてください。